How many datasets have been published in Dryad from researchers at the University of California? This question is surprisingly complicated. A short answer might be, we don’t know! A better answer could be, coming soon - stay tuned!
And a more complete and detailed answer might go something like this:
It’s not easy to determine how many datasets in Dryad are affiliated with the University of California - or any other institution, for that matter. This is the result of two main factors: (1) Dryad historically did not collect affiliation information from authors submitting datasets; and (2) even if Dryad had collected this information, it likely would have done so in a free-text field that allowed authors to write their affiliation in any number of ways (think “UC Berkeley,” “University of California-Berkeley,” or “Berkeley,” for example). Why? Because until recently, the scholarly research and publishing community did not have an easy and open option to rely on a standard set of affiliation names and related IDs to identify and disambiguate institutions.
This changed a few months ago with the launch of ROR - the Research Organization Registry. ROR is a community-led project to develop an open, sustainable, usable, and unique identifier for every research organization in the world. The ROR MVR (minimum viable registry) launched in January 2019 and began assigning unique ROR IDs to more than 91,000 organizations.
At its core, ROR is focused on filling a very specific and crucially important gap in scholarly research and publishing infrastructure: information about the organizations affiliated with researchers and research outputs. The rise of DOIs to identify datasets and publications and ORCID IDs to identify researchers and contributors has facilitated more efficient discovery and tracking of research outputs. But without being able to identify where these outputs and authors are affiliated, this discovery and tracking can only go so far. At best, an immense amount of additional and manual work is involved in extracting this information to fill the gap. At worst? The gap never gets filled in. With ROR IDs, the idea is that both of these scenarios no longer happen. ROR is intended for use by the research community, for the purposes of increasing the use of organization identifiers in the community and enabling connections between organization records in various systems.
ROR and Dryad joined forces this spring to tackle two different yet related challenges. Following the launch of the MVR, ROR was interested in finding a partner to pilot a simple yet effective implementation of the ROR API. Dryad was interested in implementing a solution to the problem of missing affiliation data. As a longstanding community partner in data publishing and open infrastructure projects, the Dryad team was eager to be an early adopter of ROR and blaze the trail toward wider implementation and collection of ROR IDs across multiple systems and platforms.
Dryad’s developers working on the new Dryad platform (launching later this summer) quickly got to work creating an affiliation field in the dataset submission form that calls the ROR API. When an author starts typing an affiliation, the field lookup searches for a matching name in ROR and shows the author a dropdown list of possible matches to choose from.
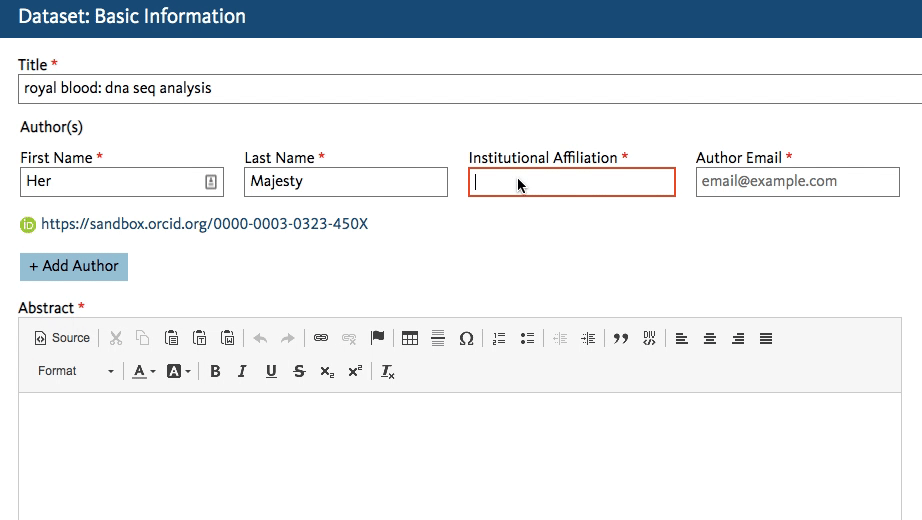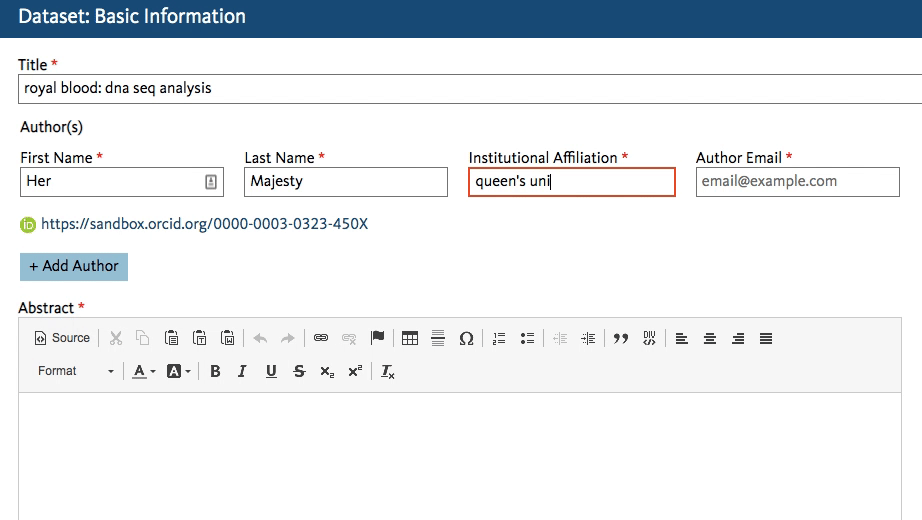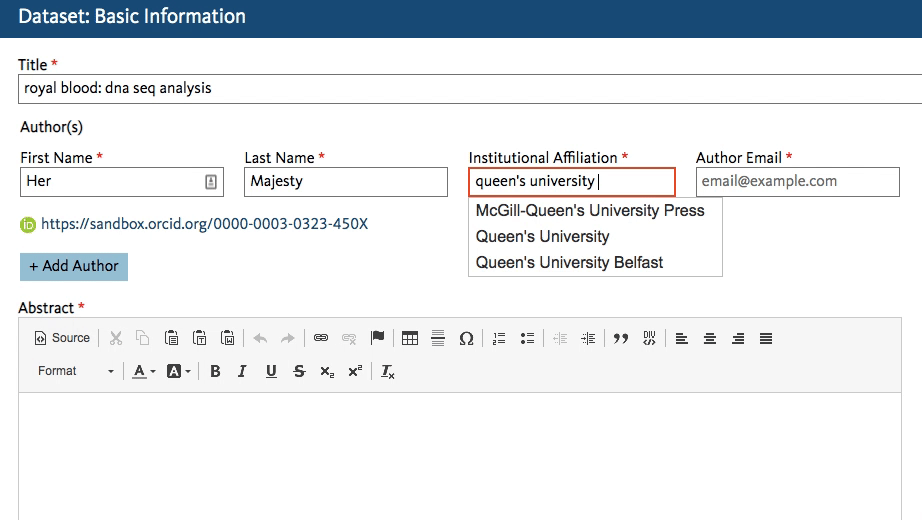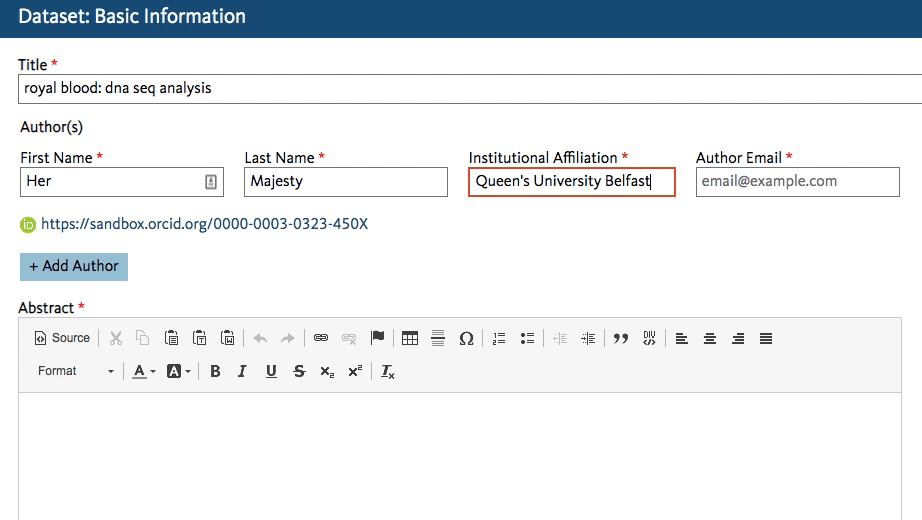
This will work regardless of whether the author starts entering a known abbreviation or the full name of the organization, as shown below.
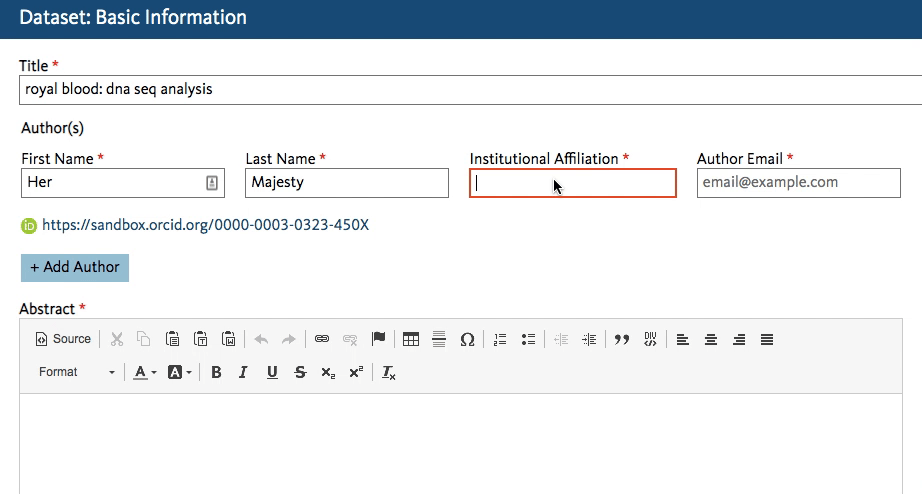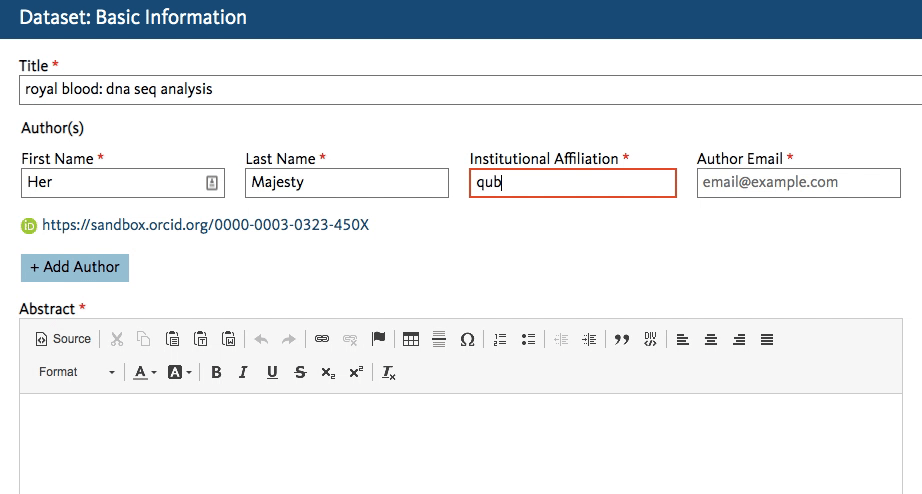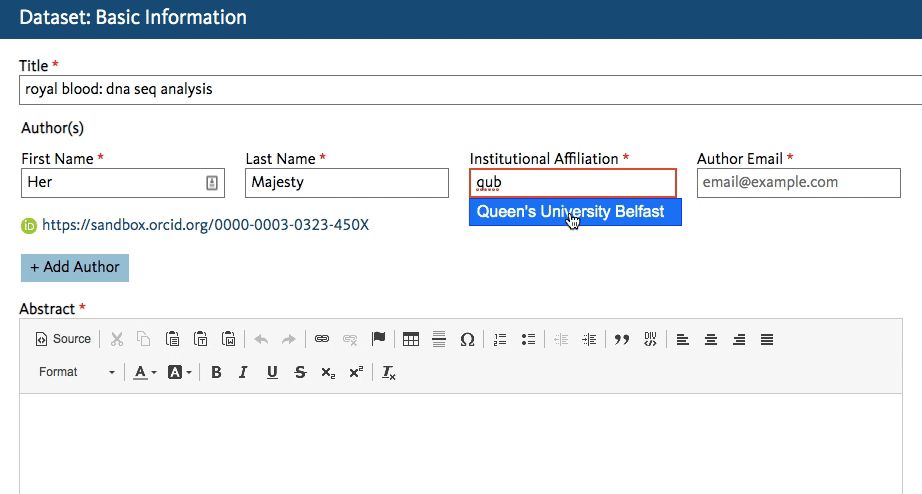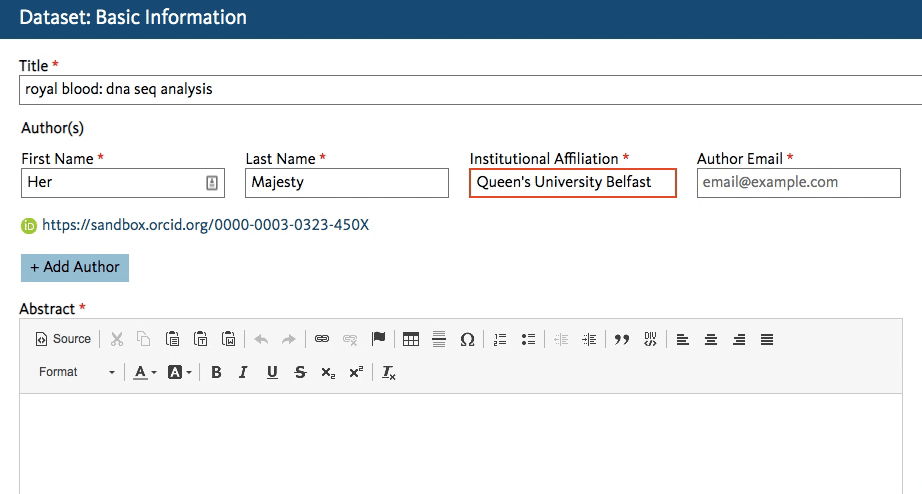
The author chooses the match and proceeds with the submission. The ROR ID is stored in the database - the author doesn’t even have to know it exists!
At this point you are probably curious about a few things: Can users override the matching and type whatever they want? What happens if a user’s affiliation is not found in the lookup? And how easy is it to implement this super-cool functionality in my platform?
We’ll address these questions in order:
Can users override the matching? Yes, the system will not prevent them from typing in an affiliation instead of choosing from the list. This is necessary to ensure a smooth submission process and also to allow for rare cases in which the user’s affiliation is not easily found in the lookup. In both of these situations, this is where Dryad’s curation workflow comes into play. A team of curators who go through each data submission will note if the affiliation is not a ROR ID, alter it if there is an existing one, or flag it for the ROR team to investigate and add to their corpus.
Now, how easy is it to implement this functionality in other systems? You can do it right now! Dryad’s code base is open-source and the team is happy to walk you through the implementation of ROR look up and autofill. To discuss the implementation you can get in touch here.
DataCite’s DOI registration system, known as Fabrica, already includes a similar lookup so this is a useful implementation to reference as an example as well.
With the ROR affiliation lookup implemented in Dryad, the future looks bright when it comes to the challenge of identifying research outputs by institution, as every new dataset submitted to Dryad will be associated with a ROR ID. But what about the datasets that are already in Dryad? As you’ll recall from the beginning of our story, affiliation details were not previously collected in Dryad at the time these datasets were submitted. This gap represents the work of approximately 90,000 researchers over the past ten years. The Dryad team wanted to ensure that these datasets had ROR IDs as well, so they teamed up with Ted Habermann (Metadata Game Changers) to identify those missing affiliations. By pulling from open APIs (Crossref, PLOS, Unpaywall, etc) and manually looking up affiliations from related articles, Ted is transforming a corpus of raw affiliations into standardized ROR IDs. Though it is a cumbersome project, this will ultimately allow for Dryad to have an entire database of ROR IDs for all past and future authors publishing their data.
The Dryad-ROR collaboration shows the promise and power of implementing organization IDs in publishing platforms to enable better tracking and discovery of research outputs by institution. We’re excited about this use of ROR and eager to see other platform providers pursue similar implementations in the coming months. Feel free to get in touch with your ideas and questions!
Maria Gould and Daniella Lowenberg are Research Data Specialists at the University of California Curation Center, California Digital Library. Maria is project lead for ROR and Daniella is product manager for Dryad.
Feed
Categories
Archives
Tags
- adoption
- annual-meeting
- api
- aps
- caltechdata
- cambridge-university-press
- clarivate
- clear-skies
- coki
- communication
- community
- cris
- cross-post
- crossref
- curation
- curvenote
- data
- datacite
- datasalon
- development
- digicorepro
- digital-science
- discovery
- dryad
- earthscope-consortium
- europe-pmc
- facilities
- fairsharing
- feedback
- figshare
- funders
- governance
- grei
- grid
- guest-post
- hhmi
- hierarchy
- highwire-press
- implementation
- integrations
- interviews
- inveniordm
- janeway
- jobs
- latin-america
- machine-learning
- matching
- metadata
- metadata-game-changers
- mps
- mvr
- nwo
- oareport
- oaworks
- open-access
- open-infrastructure
- openalex
- optica
- orcid
- osf
- persistent-identifiers
- pidapalooza
- pids
- posi
- prototype
- publishing
- registry
- repositories
- requests
- research-integrity
- researchequals
- resources
- rockefeller-university-press
- rrid
- schema
- scholastica
- scilifelab
- scoss
- silverchair
- skgs
- steering-group
- straininfo
- sustainability
- symplectic-elements
- team
- usdot
- web-of-science
- working-group
- zenodo