ROR launched in January 2019 with records for nearly 100,000 research organizations, all with unique IDs and associated metadata. ROR data is useful for a variety of reasons and for a variety of users, including both humans and machines. It is essential for ROR to have robust mechanisms for searching, retrieving, and filtering.
Since launching the registry, we have been making improvements to the codebase to strengthen and enhance these mechanisms. To start off, we rewrote the API in Python. Another change that we made was to deprecate the parameters query.name and query.names and redirect these to the query parameter to support finding organizations using specific terms.
A third improvement that we have recently implemented is affiliation matching to support searching for organizations in a full affiliation string. Previously, the API only supported specific types of tasks, like querying based on a few important terms, or filtering on specific categories like country or organization type. We heard feedback from users that they wanted the API to be able to handle unstructured affiliation strings, including those containing multiple affiliations. A number of ROR stakeholders are working on projects to explore assigning ROR IDs to existing research outputs that have free-text affiliation strings. This type of matching functionality is potentially very useful for such projects.
In the rest of this post we go into detail about what affiliation matching means, why it is useful, and how it works in practice.
What is affiliation matching - and why is it needed?
Affiliation matching refers to detecting organizations mentioned in raw affiliation strings. For example, given an affiliation string:
Department of Civil and Industrial Engineering, University of Pisa, Largo Lucio Lazzarino 2, Pisa 56126, Italy
we expect to detect the organization University of Pisa with ROR ID https://ror.org/03ad39j10
Previously, the only way to find an organization’s ROR ID based on some version of its name was the ROR API’s search functionality. This search functionality can be accessed through API’s query parameter. When a user queries the API providing a number of search words, the internal search engine scores ROR organizations according to the relevance to the search words. All ROR organizations with a non-zero relevance are then sorted according to the relevance (from most to least relevant). The sorted list is finally returned to the user.
In theory, this standard search functionality can be also used to find the ROR ID of the organization mentioned in an affiliation string. Indeed, we could simply use the affiliation string as the search query words and accept the top result as the mentioned organization. There are, however, a number of problems with this approach.
Firstly, traditional search assumes that all given query words describe the item we are looking for. Unfortunately, this is not the case when the input is a raw affiliation string. A typical affiliation string contains some form of the name of the organization, but also less relevant fragments such as the name of the department, address, author’s name, or author’s email address.
Secondly, traditional search assumes that the query words describe only one item. Again, this is not the case in affiliation matching. One affiliation string quite often contains mentions of several organizations. It would be good to be able to detect all of them.
Finally, traditional search returns a list of results sorted by relevance, but does not make any decision as to which (if any) of the returned organizations are in fact mentioned in the input affiliation string.
For these reasons, using the traditional search for affiliation matching will make the results much less precise. It will also be difficult to integrate such an approach into an automated affiliation processing workflow.
How affiliation matching works
To solve these issues, we have added a separate affiliation matching functionality to the ROR API. It can be accessed through API’s affiliation parameter, for example:
Here’s an example of how it works:
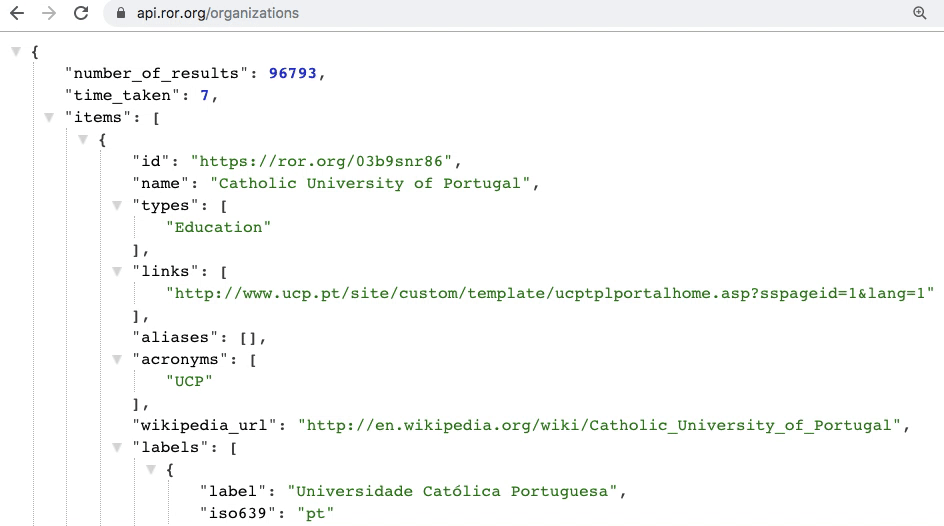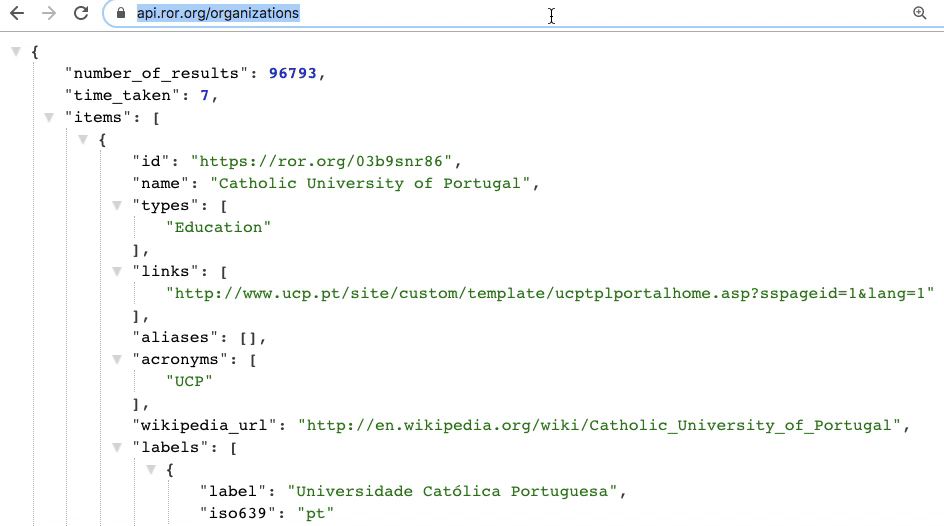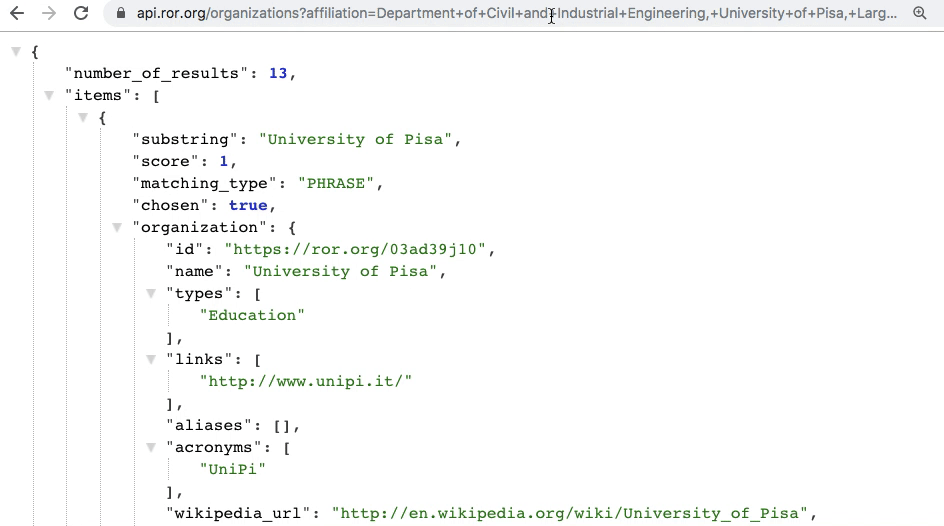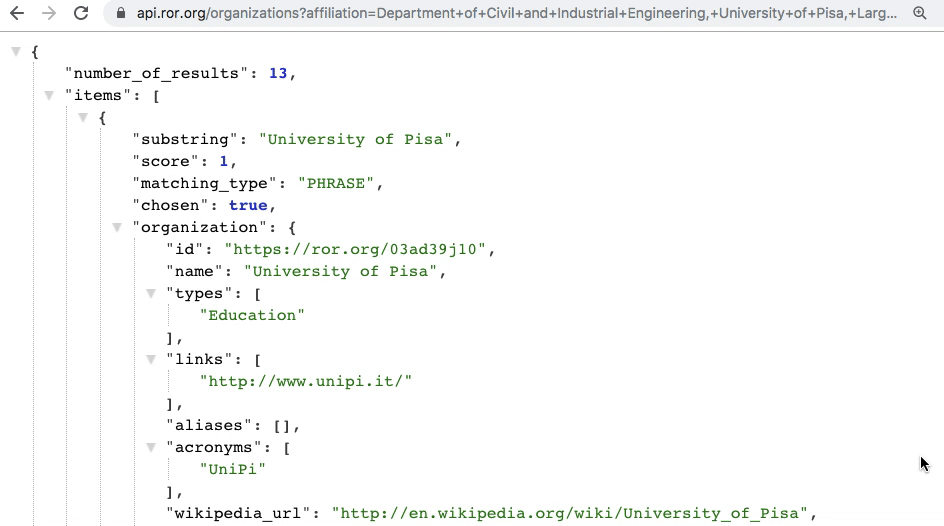
Similarly as in the case of the traditional search, the output of affiliation matching also contains a list of organizations sorted by relevance. However, there are important differences:
- Each organization in the output has been matched to a substring of the input rather than the entire input.
- Each organization in the output has a normalized similarity score ranging from 0 to 1.
- Each organization in the output has a binary field indicating whether it should be considered positively matched to a given affiliation substring. The output may include multiple such organizations positively matched to different substrings.
More information about the output fields can be found here.
How does the matching algorithm work? First, candidate substrings are extracted from the input affiliation string. This is done based on separators such as commas or semicolons. Next, each candidate substring is used separately to query the ROR API in a more traditional way. The resulting organizations are scored based on the similarity with the candidate substring. Then, the results for all candidate substrings are combined together into a final list. Finally, organizations are marked as successfully matched if the following conditions are met:
- The similarity score is at least 0.9.
- If the affiliation string contains the name of the country, it must be the same as the matched organization’s country.
- The substring cannot overlap with another substring successfully matched to an organization.
You can access the affiliation matching code here (along with other helpful API documentation). We hope you give it a try and let us know what you think.
Feed
Categories
Archives
Tags
- adoption
- annual-meeting
- api
- aps
- caltechdata
- cambridge-university-press
- clarivate
- clear-skies
- coki
- communication
- community
- cris
- cross-post
- crossref
- curation
- curvenote
- data
- datacite
- datasalon
- development
- digicorepro
- digital-science
- discovery
- dryad
- earthscope-consortium
- europe-pmc
- facilities
- fairsharing
- feedback
- figshare
- funders
- governance
- grei
- grid
- guest-post
- hhmi
- hierarchy
- highwire-press
- implementation
- integrations
- interviews
- inveniordm
- janeway
- jobs
- latin-america
- machine-learning
- matching
- metadata
- metadata-game-changers
- mps
- mvr
- nwo
- oareport
- oaworks
- open-access
- open-infrastructure
- openalex
- optica
- orcid
- osf
- persistent-identifiers
- pidapalooza
- pids
- posi
- prototype
- publishing
- registry
- repositories
- requests
- research-integrity
- researchequals
- resources
- rockefeller-university-press
- rrid
- schema
- scholastica
- scilifelab
- scoss
- silverchair
- skgs
- steering-group
- straininfo
- sustainability
- symplectic-elements
- team
- usdot
- web-of-science
- working-group
- zenodo