The ROR registry includes unique IDs and associated metadata records for 100,000+ research organizations. Each one of these organizations has at least one name. Some of them have multiple names (one even has 15)! Organization names in ROR appear in 120 different languages and counting.
Names in ROR are a key piece of metadata that helps with discovery and disambiguation of ROR records. Because organization names frequently change over time and because they can be written in multiple ways and in multiple languages, maintaining name metadata in ROR is an important and complex part of the registry’s curation process.
One of the most common questions we receive is about how we handle this process, so we thought it would be helpful to put together this blog post to share some observations and discuss our current practices with regard to organization names in ROR.
Background
ROR first launched in 2019 using seed data from GRID, and subsequent registry updates were coordinated through and synced to GRID while we worked to develop infrastructure and practices for maintaining the registry. ROR completed its multi-year transition to an independent community-based curation model in March 2022, officially diverging from GRID at this time.
Curation of ROR is an ongoing process and helps to ensure that the registry is as comprehensive as possible, that registry records are discoverable and usable, and that organization metadata is correct and reliable.
Now that the registry is fully independent, we are able to be more responsive to and proactive about community feedback about registry additions and updates. The registry is updated on a rolling basis, with new releases available approximately once a month, and the curation process is tracked publicly on Github.
Names in context: ROR aims and scope
In order to understand how ROR handles organization names, it is important to understand the wider context of ROR’s aims and scope.
ROR is a global, community-led registry of open persistent identifiers for research organizations. ROR was developed to provide an open and community-driven solution to the problem of identifying affiliations in research outputs. First and foremost, ROR is a registry of persistent identifiers for research organizations, and the registry’s purpose is to enable connections in scholarly infrastructure between research organizations, research outputs, and researchers.
In this way, ROR differs from other types of databases about institutions, because it is uniquely focused on the use case of identifying affiliations. For example, ROR is not designed to be a registry of legal entity information about organizations, because an organization’s legal name may not be the same as the organization name used as an affiliation — i.e., scholarship published by researchers from the University of California is not affiliated with “Regents of the University of California” (the university’s legal name).
ROR is also not designed to promote or rank the value or quality of a given organization’s research outputs. If an organization is included in ROR, it simply means that some research has been or will soon be associated with that organization. Inclusion in ROR does not imply anything about the quality or legitimacy of this research.
These nuances about ROR’s aims and scope are important to understand because they influence ROR’s approach to metadata curation. Let’s turn to that topic next.
The role of metadata in ROR
As noted above, ROR is a registry of persistent identifiers. However, an identifier string on its own is not very useful. This is where metadata comes in.
Every ROR ID includes descriptive metadata about the organization with which it is associated. This metadata includes the organization name, type, URL, and location, among other information. These details can be helpful in a couple of ways.
First, metadata is important for discovery. Let’s say a user is trying to find the ROR ID for Harvard University. The ID can be found by searching ROR for the name “Harvard,” because this name appears in the descriptive metadata associated with the ID. Or let’s say a user is interested in finding all of the ROR records that exist for organizations in Iceland. This information can be retrieved by querying the ROR API with a country filter that limits results to records that have “Iceland” in the country location field. Metadata is key to these discovery processes.
Metadata in ROR is also useful for disambiguation. Let’s say we are looking for the ROR record for Northwestern University. If ROR only had basic name metadata, it would be difficult to identify the right record, because there are two records in ROR with the primary name “Northwestern University.” How do we know which one is which? Since ROR includes additional information about each organization, we can distinguish between the two records by looking at the URL and location information they include (one is in the United States and the other is in the Philippines, by the way).
Metadata is therefore an important, useful, and necessary part of ROR. An organization might change over time, but its ROR identifier will not. ROR metadata needs to be able to reflect these changes. ROR metadata also needs to be understood in the context of ROR’s purpose as an open, community-driven registry of persistent identifiers. ROR metadata should not be interpreted as serving as the canonical authority on a given organization.
How names are represented in ROR
Now let’s turn to the question of how names are used in ROR.
A given ROR record may have multiple names associated with it. ROR actually has four different metadata fields that capture information about names:
- The primary form of the organization name when used as an affiliation (
name) - Translations of the primary form of the affiliation name in other languages (
labels) - Alternate versions or previous versions of the name (
aliases) - Acronyms or initialisms in use for the name (
acronyms)
Example ROR record with multiple names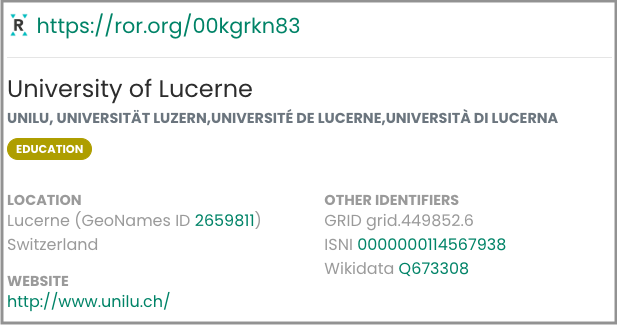
All of these fields can be useful because collectively they support the goals of discovery and disambiguation discussed above. We believe that having robust metadata for names is key for this reason. When a record has less metadata, it can be harder for users to discover the ID they are looking for, or it can be challenging to disambiguate between two similar records.
When we are creating a new record in ROR, or updating metadata in an existing record, we make decisions about which names appear in which fields based on details provided by the organization (or the person submitting feedback about the organization’s record), information available on the organization’s website and other official channels, and evidence of research activities associated with the organization. We aim to make sure that the name metadata in the record reflects the current state of the organization as well as current affiliation usage.
For example, let’s say we are working on the record for an organization whose official name is “University of ROR,” but we identify many published articles that have the affiliation written as “ROR University.” In order to make sure these articles can be associated with the correct ROR ID, we include this name variation — even though it is not official — as an alias in the record.
Common themes with name metadata
As we curate the ROR registry, we spend a lot of time making sure that metadata for organization names is accurate, up to date, and comprehensive. A few common themes come up in this work.
Language
As mentioned above, ROR was built with seed data from the GRID database of institutions. GRID had a policy of defaulting to English-language names in the primary name field. Because ROR was initially synced to GRID, ROR inherited this metadata and the majority of organization records have an English-language name in the primary name field.
Now that ROR is being maintained independently, we have received feedback that this practice is not always appropriate in certain situations. We therefore have been publishing organization records with non-English primary names when this is requested. We are also performing a more comprehensive analysis of our records to identify other changes that should be made to existing metadata.
One exception to this practice is that the primary name field currently supports Latin characters only according to the ROR schema. We will be looking into changing this as part of a larger effort to evolve the ROR schema. Another challenge is that the primary name field does not currently include language tags. This is another area that we would like to improve in future schema changes.
Affiliation names vs. legal names
Because ROR’s focus is on identifying affiliations, the name used in an organization’s ROR record might be different from that organization’s legal name. When making decisions about the primary name, we look to published research outputs and scholarly databases to understand current usage of the organization name as an affiliation. If it is not clear that the legal form of the name is actively used as an affiliation, it may not be included in the metadata record.
Name variations
Many ROR records include translations of the organization’s name in multiple languages, or shortened or alternate versions of the primary name. We sometimes receive requests to remove these variations from the record. However, our general practice is to retain these variations. As discussed throughout this piece, the metadata in ROR serves to support discovery and disambiguation; it is not meant to serve as the canonical name authority for a given organization. If there is evidence of research associated with those versions of the name, the metadata in ROR reflects this.
Future directions for name metadata in ROR
As we continue to improve the quality and coverage of organization metadata in ROR, we plan to focus especially on name metadata. This will be a key component of future schema changes, which we will be exploring in the coming months with input from community stakeholders.
Another area of focus for the future is analyzing current name metadata across the registry to identify opportunities for metadata enrichment at scale. For example, we are looking at all records where the primary name is not in English and reviewing them for the completeness and quality of a corresponding English label.
We also work to support those who are integrating ROR in their systems to help them develop implementations that can leverage the full breadth of name metadata (and additional information) in ROR. Implementation guidance is available on the ROR support site.
Bringing it all together
To sum up these thoughts: in this discussion about handling name metadata in ROR, we aim to underscore a few key concepts:
- ROR’s primary purpose is to be a registry of persistent identifiers for research affiliations
- Metadata serves to support discovery and disambiguation of ROR records
- Metadata in ROR is not the same thing as legal metadata about an organization
- ROR records are more useful when they have more metadata
- Names in ROR are a key part of the metadata for each record, and it is useful to have multiple names associated with each record
- ROR is a community-curated registry that is responsive to community feedback
We hope this explanation has provided interesting insights into the work we do at ROR to support rich and useful metadata associated with every ROR ID.
Curation is an ongoing effort and we invite community users to become more involved in this work through participation in the curation advisory board and/or through community discussions.
If you have questions or feedback, or if you would like to get more involved in curating ROR records, please get in touch via support@ror.org.
Feed
Categories
Archives
Tags
- adoption
- annual-meeting
- api
- aps
- caltechdata
- cambridge-university-press
- clarivate
- clear-skies
- coki
- communication
- community
- cris
- cross-post
- crossref
- curation
- curvenote
- data
- datacite
- datasalon
- development
- digicorepro
- digital-science
- discovery
- dryad
- earthscope-consortium
- europe-pmc
- facilities
- fairsharing
- feedback
- figshare
- funders
- governance
- grei
- grid
- guest-post
- hhmi
- hierarchy
- highwire-press
- implementation
- integrations
- interviews
- inveniordm
- janeway
- jobs
- latin-america
- machine-learning
- matching
- metadata
- metadata-game-changers
- mps
- mvr
- nwo
- oareport
- oaworks
- open-access
- open-infrastructure
- openalex
- optica
- orcid
- osf
- persistent-identifiers
- pidapalooza
- pids
- posi
- prototype
- publishers
- publishing
- registry
- repositories
- requests
- research-integrity
- researchequals
- resources
- rockefeller-university-press
- rrid
- schema
- scholastica
- scilifelab
- silverchair
- skgs
- steering-group
- straininfo
- sustainability
- symplectic-elements
- team
- usdot
- web-of-science
- working-group
- zenodo