This conversation with Eric Olson of the Center for Open Science is the first in a new series of interviews, “Case Studies in ROR Integration,” a series designed to provide in-depth detail on why and how people are choosing to integrate ROR IDs into their systems.
Key quotations
“[W]hen we mint DOIs for all the content types that we have DOIs for – which right now are preprints, preregistration documents, and project spaces – we send the ROR IDs from the affiliation data that’s associated with the user profile with the metadata for each contributor.”
“The really cool stuff that we have just done with the ROR integration will allow us to continue to build in the direction of describing relationships.”
“[W]e want to be part of that movement: being able to visualize the relationships between one DOI and all the people and places and other things that it’s related to.”
– Eric Olson, Product Manager, Center for Open Science
Amanda French
Thank you so much for agreeing to tell us about your ROR integration. Can you start by telling us your name, title, and organization?
Do you work on a particular product? Or are you a product manager who works on multiple products?
Eric Olson
We do have multiple products, but the product that we are actively developing and maintaining is the Open Science Framework (OSF), which itself has many, many tools involved in that one platform. But you know, as a community-driven organization, there are other products in the landscape that are involved, like ROR. So that all falls under our infrastructure product team.
Graphic provided by the Center for Open Science
Amanda French
Tell us about the Center for Open Science.
Eric Olson
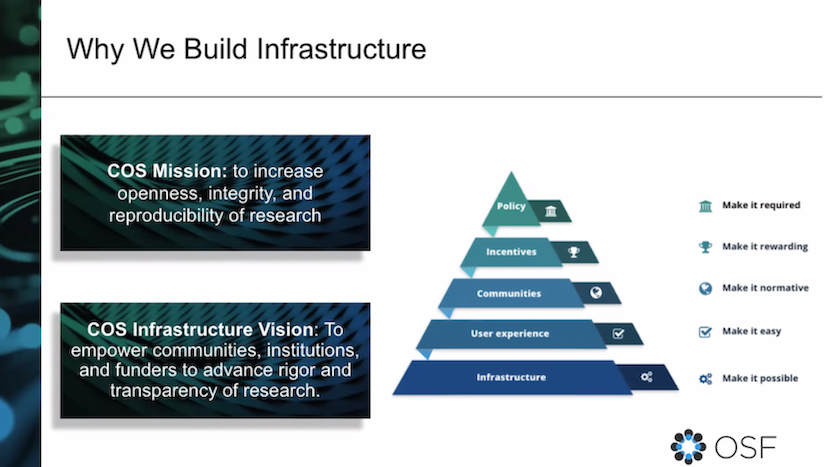
Our mission is to increase the openness, integrity, and reproducibility of research. We are a culture change organization. And that mission can’t be accomplished by any one change or any one stakeholder. The OSF, while it’s extremely important to us and has over half a million users, is just one means of accomplishing our mission.
COS works on the diffusion of innovations. There are early adopters who, if you give them the most exciting practice, they see the value in it right away. And they want to run right to that. All of us in the infrastructure space, including in persistent identifiers, are in exactly the same boat. The question is, “How do we even make it possible for researchers to do those innovative open science things that they’re super excited about?” They really want to do them, but they need something to enable those things to happen.
So on the infrastructure team, our primary goal is to make it possible for researchers to participate in the open practices that we are advocating. We get those early adopters, and because early adopters are usually very exciting, and what they’re practicing is very exciting, they also pull people with them because they just have a gravity to how enthusiastic they are and can demonstrate benefits to what they’re doing. So we don’t just throw the tool at them and say, “Go use this.” We continue to iterate on it, make it better, make it easier for researchers to use, easier for the next group who might not be the earliest adopters, but who are willing to give this a chance if we make it continue to make it easier for them. And that’s what we do at the infrastructure level.
We have other teams at the center that work with policymakers, funders, journals, publishers. They’re advocating for practices and policies that align with the mission: openness, transparency, integrity, and reproducibility. We also have a research team, what we call the metascience team, that looks at the “science of science” and determines if the practices that we advocate and the tools that we provide are actually moving us toward the mission. And if they aren’t: Do we need to take a step back and figure out what we’re missing? Where are we not meeting researchers where they are?
Our theory of change for creating more openness is that researcher communities determine that “this is the thing we should do.” And researchers don’t need to be forced to do it, even though they might have been encouraged to do it by their funders and their institutions. We give them the tools to do it. And then those communities just make that a normal thing that researchers are expected to do, and then the rest of their community is going to continue to come along with it, because that’s the expectation. So it’s getting these open, transparent practices in scholarly communication to be among those norms that that researchers and research communities and research institutions normalize as part of their practices and their expectations.
Amanda French
Great. So since we are talking specifically about the ROR integration into OSF, can you tell us a little bit more about OSF, the Open Science Framework?
Eric Olson
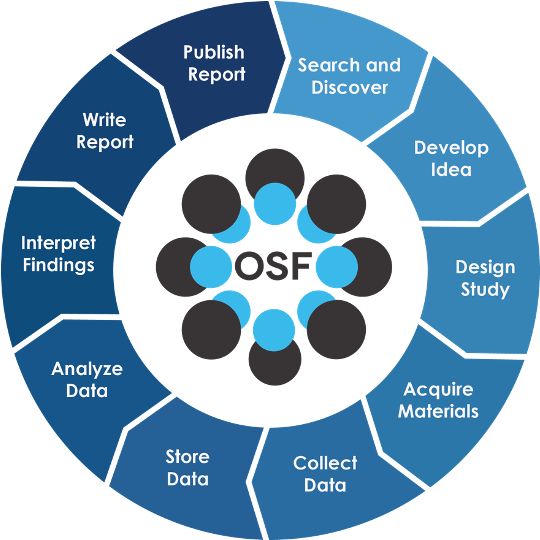
The OSF is a research, management, and planning platform that, as I mentioned before, has a lot of tools, because it wants to provide tools at each stage of the research lifecycle – elements that the researchers can rely on so that they can bundle lots of stuff: their planning, their files, their data that’s an outcome or an input into their research, their collaborators, their protocols. All those things might have previously been scattered in lots of different places, so if someone asked them, “Can you put all this together for me along with your paper so that I can try to reproduce your study?”, the amount of effort involved, if it were even possible at all, would be pretty significant. Whereas on the OSF, you can have your data stored on the OSF or linked to another storage provider, you can write out your protocols, you can do what we call “pre-register”, plan out your studies even before you go and gather your data and document them with a timestamp. And have all of those be discoverable and do all that in one location. And we don’t want to duplicate what other tools do, so we integrate with storage providers, with citation managers, and with persistent identifier infrastructure to take advantage of the really cool stuff they already do that our users already use. And so those just become part of those available workflows in the OSF.
So let’s move on to ROR, The Research Organization Registry. Do you remember where and when you personally first heard about ROR?
Eric Olson
Yeah, I can. And it’s been really exciting over the last year or so to see so much manifesting in the ROR space. Because I first heard of it in 2018 while I was on the ORCID team. We obviously heard a lot about persistent identifier progress in the community, and at PIDapalooza in Girona, Spain, there was a kickoff of “What is this thing going to be?” And I was fortunate that I was there early and was able to attend that with several members of the team that you’re on now, like Liz Krzarnich.
And it was really cool to see very early what the anticipated concerns were. Not just with the technology, really, that was not what they were concerned about at all. It was “How do we make this continue to be a community-driven initiative like ORCID and Crossref and DataCite?” You know, we’re already living that! So it’s “How do we create something that is not going to reproduce the problems that the other organization identifiers have, but instead can be something that is community-owned and governed and understood?” I’ve always been a fan of PIDs that can represent the key elements of our work in scholarly communication. And there were previously and there are still other organization identifiers, but to see one that actually aligns with what the rest of the PID infrastructure that we’re working with in scholcomm was really a huge opportunity. And it’s really exciting to see it all take off and be where we are.
And we’re now at the stage where although there are plenty of things we can do, the tech is really very mature, compared to then.
Eric Olson
Yeah. It was barely past the inheriting GRID phase at the time. And there were still lots of questions about “What do we represent here?” Hierarchy was always a big debate, and it still is.
Amanda French
Yep, yes indeed. So who were the primary advocates of implementing ROR at your organization?
Eric Olson
The OSF has supported PIDs for years – DOIs and even Ark IDs have been in the OSF for years, though not always implemented in the way that they are now. We always knew that this was the direction that the community was headed, and we’re carving out the space for it. And ORCID IDs were also added prior to my arrival. And when I got here, ROR just seemed like a really great opportunity, because we were working with these institutional partners to give them insights into what their communities are already doing on the OSF. And because we have high confidence that those users are part of those member institutions, that we know who they are, it just made sense to also send ROR IDs for all these DOIs we’re minting on behalf of the users that come from those institutions. And so for those institutions, it instantly adds some additional value for them.
And it starts to complete the loop, you know, for PIDs. We have PIDs now for people, places, and things to go along with globally unique identifiers that we use within the platform. There’s still room for us to grow there and make it more nuanced and add more identifiers, and those are coming. But for the product team, ROR was definitely on our radar very early on when we were aligning with our institutional partners a couple of years ago.
Amanda French
Why did you decide to implement ROR at the time you did? What was it that sort of pushed you over the edge from being a supporter to being an integrator?
Eric Olson
The OSF has so many workflows, and so many tools that we support, and so many integrations with other PID providers and with other storage and citation managers, that prioritization of new integrations in particular is a bit of a negotiation for us internally. As we continue to mature the OSF so that that promise of having tools across the research lifecycle can really be met, the key is iterating sort of a piece at a time so that as we mature, we don’t sacrifice other parts of our infrastructure. Having some maturity on our institutional models was part of that. And we continue to work on making those services better and providing more reliable metrics for our institutional partners. And this was a part of that: it provides more insights for our partners, our institutional members, while also continuing to implement more parts of the PID Graph.
Since then, we’ve added a couple of more pieces to this, so it’s kind of PID dominoes. Starting earlier this year, it just made sense to start doing these updates and getting the metadata ready to take in more information than we ever did previously. We made a lot of changes to what kinds of information we can collect from users, or know about users and their content, so that we could send those to DataCite and Crossref in the most effective ways. And we had to align all of that up so that it works, without making assumptions about a user and their data. It took a bit of trial and error there. But now we’re in a place where we have more metadata options that are coming soon, and we can continue to send this new metadata to DataCite and Crossref.
So really, the timing lined up, because we have a lot of PID and metadata projects that we’ve just completed or that we’re in the process of completing through the beginning of next year that are going to support a lot of researcher needs as well as funder and institutional needs. Being able to see Who funded this research? What institution is it associated with? Who are the collaborators? All of those will be able to have PIDs, so it’s not a mystery anymore to unlock the box. Where’d this come from? What’s it about? Who provided support for it? It’ll all be reliable connections that describe those relationships.
Amanda French
I really like your image of PID dominoes, because you hear all these metaphors about networks and ecosystems and landscapes that try to capture how PIDs interact: a DOI for the output and a ROR for the institution and an ORCID for the researcher. But there is a sense in which everyone needs to adopt all the PIDs at once in order to create the full picture.
Yeah, and it’s overwhelming to hear that if you’re an institution, you know, as just one corner of all the places that provide and use PIDs. To say, “You have to get everybody on your campus signed up for ORCID IDs, get their affiliations on, and make sure they have their syncs turned on” – which are just miracle workflows, you know, but you still have to get them to do it, and it sounds like a whole lot. And so part of why we at the Center for Open Science do this is if we’re going to advise that these are good things to have your researchers do, this is part of open science, it really only makes sense that we would enable the things that we’re advising them to do. So it’s just walking the walk that we articulate as the right path.
Amanda French
I’m going to ask you now to describe how you’ve implemented ROR in your system. Where does it fit into your workflow? Does it fit into multiple places in your workflow? Can users see the ROR ID? What ROR tech are you using? Is it the API or the data dump? I’m actually also interested in this idea of affiliation verification since you’ve mentioned that a couple of times. Can you talk about why that’s important for you?
Eric Olson
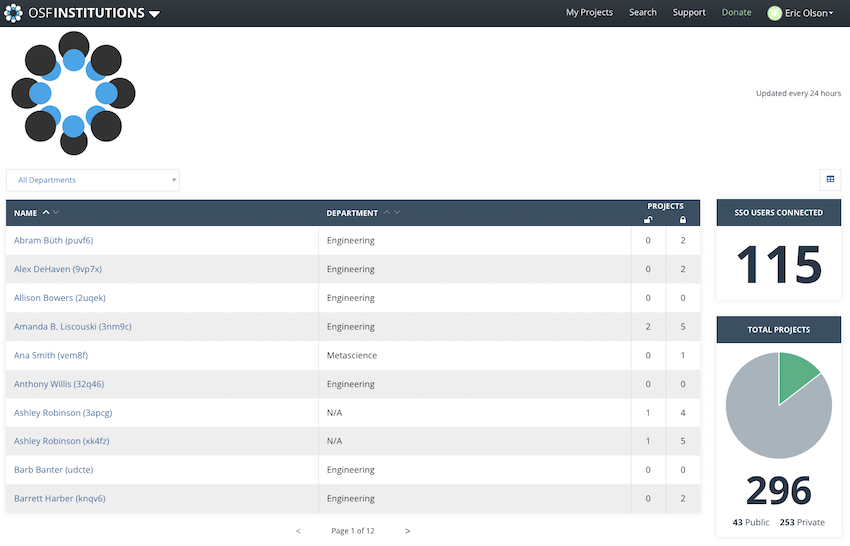
Currently, the way we have this implemented is that we have a service within the OSF where institutions can choose to have public content from their affiliated researchers be visually identified with that institution.
Graphic provided by the Center for Open Science
And the way we do that is that an institution becomes a Service Partner with us, and we set up single sign-on (SSO) into the OSF using their credentials, using their systems, which for a number of institutions is a critical part of identity management. I won’t speak for all institutions here, but for some of them, they don’t want users to be using a lot of tools without something that gives the institution the ability to give the “go or no go.” And so that’s what we provide, is a single sign-on access for each institutional service partner. And if the user attempts to sign in as a member of an institution that they don’t belong to, then they will not get access to the OSF that way, although they can access it in a different way.
If they do sign in as a member of an institution, then they now have that institution associated with their profile. And they can be part of multiple institutions; I myself am part of two.
Graphic provided by the Center for Open Science
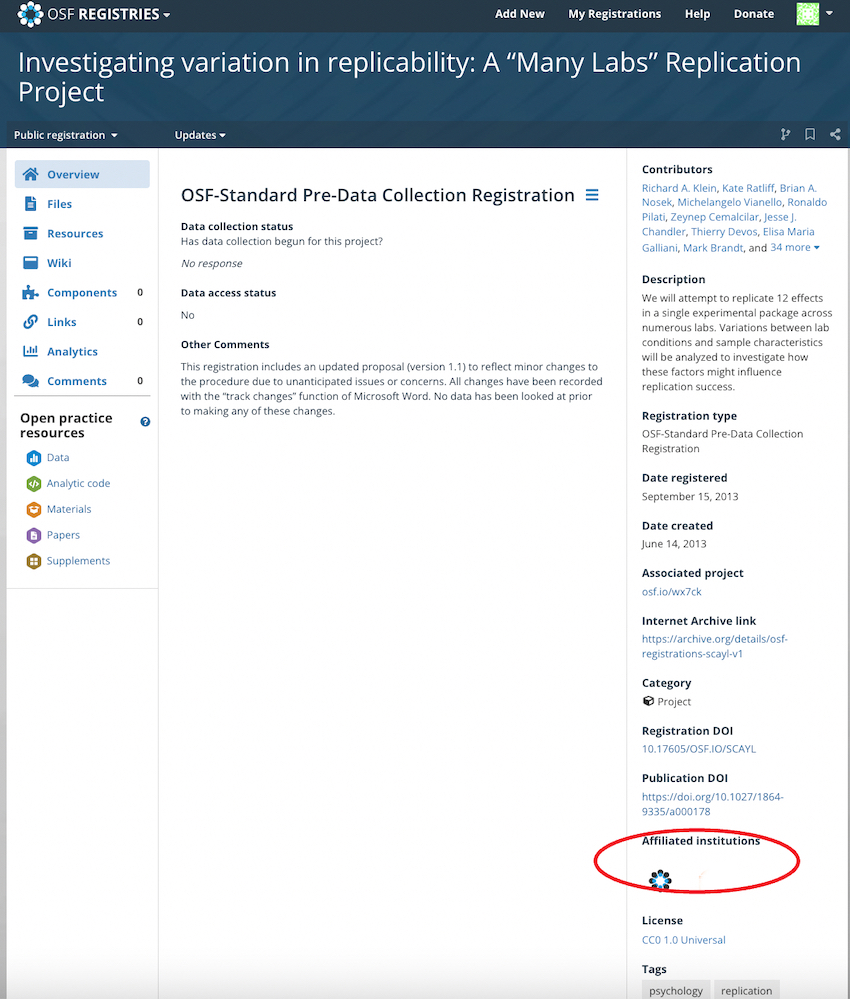
And when they are working on content, they can add a visual brand based on their affiliations, and they can add that branding to their content.
The user and the content can have multiple affiliations. If you and I are both creators of the same piece of content, we can each have a different affiliation, and we can each have multiple affiliations. But I can’t make that claim on your behalf; you’d be adding it yourself. And so that’s how we deal with it within the OSF’S ecosystem. We verify based on that single sign-on that a user is associated with an institution.
And then when we mint DOIs for all the content types that we have DOIs for – which right now are preprints, preregistration documents, and project spaces – we send the ROR IDs from the affiliation data that’s associated with the user profile with the metadata for each contributor.
So you’ll see for each contributor what their affiliations are rather than getting them all blended together in the metadata that we send to Crossref and to DataCite.
So that’s where we’ve started, because we know that those individuals are part of those institutions, so we have very high confidence that those affiliations belong with those individuals and their content.
And we are looking at ways to implement ROR beyond that so that you can self-identify your institution. There are a number of technical things we have to work through to do that, so that we’re enabling them in ways that for one takes advantage of the ROR API so that users choose based on a ROR query rather than a free-text field, which certainly would not help us verify anything, because it could be wrong, or just different than the way the institution includes their information. So that’s something we’re still working on. Currently, we associate a ROR ID with each of our current institutional partners and with each new one that comes aboard. And, yeah, that’s it.
Amanda French
Gotcha. What challenges did you run into as you were integrating ROR into your systems?
Eric Olson
Part of the challenge was that we were adding ROR to the metadata that we send to DataCite and Crossref at the same time as we were adding other additional information to send and preparing for even more information that’s coming. Well, actually, some of that we’ve added since we did the ROR work, and there’s more coming soon. So we made a lot of changes and prepared for even more changes all at the same time. And so each time we would, you know, try to make the change, as soon as we hit one error, the whole thing would fail – which was good, because we didn’t want to upload a bunch of data that was wrong. So it took us three attempts to get it all lined up and ready to be sent properly and update it so that the ROR IDs are available for all content going forward as well as backfilling content that is eligible for ROR IDs to be added to that metadata. So we updated a lot of DOIs with that rollout.
I guess the key challenge is that we did more than ROR all at once, so we had to really get it lined up properly in order for it to work.
Amanda French
What benefits to you and your users is this ROR integration currently providing?
Eric Olson
A big part of it for us is that this is something that we get to tell our partners and other institutions beyond us. Implementing the PID graph, as we talked about before, creates a lot of opportunities. If you have the ORCID IDs and you’re minting DOIs, or if you’re using some other identifier for a specific use case, and you can use ROR IDs, then you have a lot of information that’s unlocked that way.
And these things are going to be used. If they’re not in use yet, they’re going to be adopted by the other stakeholder groups that researchers are working with and rely on, like publishers and like funders. These things are coming. So we want to – not just be out ahead, that’s not the goal, but we want to say that we are advocates of this adoption, and that we’re so confident in the reliability of this great infrastructure that we’re going to do it. And we’re going to do it now: we’re not going to wait for it to get to the tipping point. Even though we’re on the precipice of that, I’m sure. But we want to get there and help that happen.
For some of our partners, this is not really something that’s on their radar yet. Or it might be, but it’s under the surface a little bit. And that’s okay. We’re still going to talk about it, that this is something that’s really advantageous. And they’ll be seeing more of it one way or another, so we want to enable those things in our workflows, enable ROR, enable more relationships between DOIs and other DOIs, and with person and place IDs and grant and funder IDs, those are all either there already, or coming.
And then it’s about all those lifecycle pieces in the OSF. Getting to a consistency with these cool features, so that they’re not just in one part of OSF but in all the tools in the platform.
Graphic provided by the Center for Open Science
We’re still catching up with updating some parts of the OSF to take advantage of all this cool stuff. But that really is the goal, is to be able to demonstrate the things that we articulate as very valuable. We want to take part in those practices not just because they benefit our tech, although we thoroughly believe that they do, but because we want to lead by example. It’s part of our theory of change to help not just the early adopters, but everyone – to make it easier for researchers to find the change they need, to see that these things are possible.
And if the OSF can provide that, that’s great. But if someone just reads about all this cool stuff that we’re talking about and realizes that another tool is actually better because it does these things in a different way, that’s okay too. That’s still pushing toward our mission, in our theory of change, when people work with other tools, tools that a lot of times we work with ourselves. So I think that’s the key, is that it’s not just a benefit to the OSF but really to our entire mission. And this is really a critical opportunity to describe the change we want to see in open infrastructure.
Amanda French
So that leads right into the next question, which is: What benefits – maybe specifically tools, reports, that kind of thing – do you hope or expect to get from ROR integration in the future?
Eric Olson
The really cool stuff that we have just done with the ROR integration will allow us to continue to build in the direction of describing relationships. We’ve already added ways to describe relationships in our registration workflows: you can add the data and the materials and the code, all the outcomes or inputs into your research, you can link the DOIs and describe those relationships. Having the ROR IDs and the ORCID IDs be effectively implemented and displayed for both ORCID and ROR is something we still have to get to. But that’s something we have for one-quarter of the workflows that we have.
And now the question is: Can we enable this for more parts of the platform so that there are even more ways to describe all of the things, whether they’re on the OSF or not? That’s the key here: you can have your things stored with a DOI somewhere else, you can have your code on Zenodo, you can have your data stored in your institutional repository, you can have your paper published by Nature, all of those things you have different DOIs for that articulate the connection to your preregistration, and then we send all that to DataCite, including the ROR ID if we have it. And so right now the task is to capture all of this information.
And then, you know, really what we are looking for, just like many other institutions and tools, is How can we learn from what’s been captured? How do we provide a picture, you know, a window into that? We have analytics tools that are available in the OSF currently, but they aren’t getting into this yet, where they are exploring these relationships. And that’s going to be going to be a while yet, but that’s really what we’d like to take advantage of. And we’re not alone in this, because we have open APIs that can get a lot of this information, so we don’t have to be the ones that develop it, even.
But we want to be part of that movement: being able to visualize the relationships between one DOI and all the people and places and other things that it’s related to. And that really is the promise of the PID graph: being able to click a button and see what other institutions and what other regions worked on this project. Is there data connected to this paper? Who are all the individuals that contributed, and then if I click on the individual, can I see all their other stuff? How do I break that open? There’s still work to do there, but we’re getting the data to enable it now. We’re at that point where we’re collecting what we want. The Funder IDs are coming soon. So it’s going to be rolling into the next step of exposing all of that in creative and effective ways. That will really be the next step. But all this data is going to be available, so anybody can start to explore it. And our role, just like we said before, will be to make that easier as a next step to get at that information.
Amanda French
Great! This was tremendously interesting – thanks for telling us all about your ROR integration.
Questions? Want to be featured in a ROR case study? Contact support@ror.org.



{kind=link}