In this installment of the ROR Case Studies series, we talk with Allyson Lister, Content and Community Lead for FAIRsharing, a cross-disciplinary registry of scientific standards, databases, and policies, about how and why FAIRsharing used ROR to help make organizations first-class citizens in their data model.
Key quotations
“If we’re going to integrate with somebody like ROR, we have to commit to it, you know. It was intensive at first, but mainly because of the creation of the original scripts and the batch of curation checks, as our records are all curated. But we’ve had a couple of these three-month checks since, and it’s been an hour or two maximum of checking, with the main curation team each doing maybe fifteen minutes or so of checking.”
“The integration itself was smooth. Those challenges I mentioned, the fact that we had to do string comparisons, and the fact that we don’t have the same scope, those aren’t large challenges. Honestly, they’re just natural differences when you’re doing a bulk match against another repository.”
“So we have something like 3,500 organizations in FAIRsharing, which is nothing compared to, what is it? A hundred thousand [in ROR], or something like that? … Ramon took our organizations and pulled the information from your API, and calculated an ’edit distance,’ so he looked at the name and the abbreviation and the home page fields for ROR and for FAIRsharing and he calculated the distance between the two terms for all of them, finding the least distance, the closest match.”
– Allyson Lister, Content and Community Lead, FAIRsharing
Amanda French
So, Allyson, please tell me your name, title, and organization.
Allyson Lister
I can do that. I am Allyson Lister, and I am the FAIRsharing Content and Community Lead. I work with Ramon Granell, who is a Research Knowledge Software Engineer, who unfortunately isn’t able to join us. We’re both staff at the University of Oxford at an institute called the Oxford e-Research Centre (OeRC), which is a cross-disciplinary center.
Amanda French
So can you tell me both about that Institute and about FAIRsharing? What do they do, and what makes them special?
Allyson Lister
The OeRC started in 2006, and was created as a cross-disciplinary research Centre in digital methodology, working across the humanities, communications, engineering, life sciences and more. And for FAIRsharing, we started in about 2009 as the result of an article in Science that was authored by a number of different research councils, research institutes, and funding agencies and led by my boss, Professor Susanna-Assunta Sansone. As a result, BioSharing was created, which was intended to collect all the existing data policies within the life sciences to ensure they could be compared and harmonized according to the resources they recommend. You know, the standards they recommend, the databases they recommend. And this was so popular that it changed in 2011 from this original blog site to a website launched from the University of Oxford. And so it continued to grow over the next few years, including under the auspices of an RDA working group. That’s the Research Data Alliance. Are you familiar with them?
Amanda French
Yep.
Allyson Lister
They are a fantastic, absolutely amazing, volunteer-led community organization for research data. And so that went along quite merrily for a few years, until the publication of the FAIR principles in 2016, which Susanna and two other members of our group at the time were authors on, among a bunch of other authors. And so, when the FAIR principles were published, we quickly realized that the best thing to do was to change the scope of BioSharing to be more than life sciences. And so it became FAIRsharing in 2017. And now it’s cross-discipline, looking to store information about databases, standards, and data policies across all research areas, because these are really the pillars of the FAIR principles; they give you the ability to describe the places you store your data, the way in which you format your data, and who is asking you to store and structure it in a certain way (such as funders, journals, societies). And so this is where we are now: a curated registry. Or, in reality, a curated set of three registries for (meta)data standards, databases, and data policies.
FAIRsharing home page
FAIRsharing doesn’t just describe those resources; my favorite part is that it links them together. So it creates this network of all the relationships, the landscape of resources for a particular domain. It allows you to explore what’s available for your particular research area. And it’s been adopted not only by the RDA, in which it continues to be an active member, but also a number of other international organizations and funders, such as EOSC and FORCE11. We have all these different organizations and publishers – journal publishers, funders. And the operational team is advised by Executive and Stakeholder Boards that we use to make sure our direction is right for the community that we serve. And I think that’s about it. Later on I’m going to touch upon my favorite bit, which is that I’m running this community curation program that is bringing our domain experts even closer into the project to help them showcase their resources.
Amanda French
Oh, wonderful! So where and when did you personally first hear about ROR?
Allyson Lister
I felt like I’ve always known about ROR, at least ever since we started looking outward. The first few years, it was all about curating the resources. So we were very focused on the databases and standards and policies, and we always linked to organizations. But we didn’t have any way of unambiguously referring to them other than our own internal curation checks. And then at the beginning of 2022, when we redeveloped FAIRsharing and created a brand new data model and a brand new front end, we said, “What we need is for organizations to be first-class citizens.” And so I immediately thought of ROR. Because what you get is an unambiguously, persistently-identified set of research organizations that will fix a lot of the problems that we had found. It wasn’t a huge issue, but there were cases where we had redundancy in our organizations. And so we did a big push to align our organizations with ROR organizations.
Amanda French
Right.
Allyson Lister
FAIRsharing is a part of the Data Readiness Group. As well as working with data transparency, we also look at research integrity and making data FAIR for humans and machines. And so at FAIRsharing we are looking to incorporate many different international community activities around research data management. So ROR was a natural place to go to for organizations.
Amanda French
Well, it’s interesting, because I think the timeline of FAIRsharing and ROR overlap quite a bit, because the planning for ROR began really in 2016, and went on through 2019 when it officially launched, which is sort of right when FAIRsharing was making the move to become FAIRsharing.
Allyson Lister
Exactly. We became FAIRsharing officially in 2017, but by 2018, 2019 we were really starting to snowball into the other communities. The life sciences had already heard of us, because we are a part of ELIXIR. We are a recommended interoperability resource in ELIXIR, which is one of the parts of EOSC Life within the broader EOSC context. I was at the EOSC symposium in Prague a few weeks ago, and everyone was clear about the interoperability aspects being really important. And I think that’s something that you need to be very proud of at ROR, because you are the one connecting and making sure that people are saying what they mean to say when they’re talking about organizations.
Amanda French
And that does lead into a question that came up when you were talking about your own awareness of ROR which is: did you consider any other organizational identifiers when you were refactoring FAIRsharing?
Allyson Lister
You know, I’m trying to remember if we did, or if once I heard of ROR, it just made sense. Ramon has told me that your API was really easy to use, and this is really important when developing an integration like this one.
Amanda French
That’s very good to hear!
Allyson Lister
He said the API was never the issue. The issue was the classical natural language processing issue, you know, of comparing, making the initial comparison against what we already had from 2011 onwards to what you guys had. But I’m trying to remember if there were any other major contenders. I have to say that ROR is the one that you always hear of in presentations. ROR is the one that you’re always referring to when people are talking about it, and it just seems … I don’t know exactly what your perspective is, but from my perspective it’s the de facto way of describing organizations. And there are bits of the ROR scope that don’t align with FAIRsharing. I’m not saying that’s a criticism of ROR. There are some places where we can’t match our organizations to ROR, and that’s not a limitation as much as just an acknowledgment of the differences in the way that people describe an organization. Because you could go on in workshops for days about “What is an organization?” And I’m sure you have, being ROR! So it’s just about deciding what you want to describe, and clearly listing what those requirements are, and for ROR that’s very clear. You go the on the website and you can click straight away and find out what your scope is.
Amanda French
Wonderful. So let’s get into the “How” at this point. Describe how you’ve implemented ROR in FAIRsharing. Tell us about that.
Allyson Lister
Well, in our old version we had a very nice web form that a lot of people used, that allowed you to “free-text add” everything about an organization, and while that organization could be reused, it was an object local only to FAIRsharing. Equally, while there weren’t a hundred different versions of “University of Oxford”, we did see duplications and mistakes creeping in. This was also true for ORCID IDs before our integration as a trusted partner with ORCID and for our subject areas and our technical domains, which were free text in the earliest versions of our project. So we wanted to align with community ontologies. We wanted to link up with ORCID. We wanted to link up with ROR. So this was our opportunity when we re-wrote the data model. You know, I wrote in my notes for this question that I wanted to mention xkcd and Randall Munroe. I have to!
Amanda French
I know the one you’re talking about, of course!
Allyson Lister
Yes, the reinventing of the wheel. The 14 standards we have, we must make another one to align them all, and then we have 15 standards. We try our hardest when we’re all aligning, wanting to align with FAIR principles, to ensure that we’re not making this kind of mistake. Inevitably there’s going to be some, but we do our best at every stage not to do that. So our subject tags and our technical domain tags all come from community ontologies. We use nearly 60 different community ontologies that we’ve merged together to try to create all of the tags that our users had already put into the system. So you know, most people would say, “Let’s find an ontology we like, and that’s what we’ll provide our users.” But we had had seven or eight years of users putting whatever they wanted, self-describing their records.
Amanda French
Right.
Allyson Lister
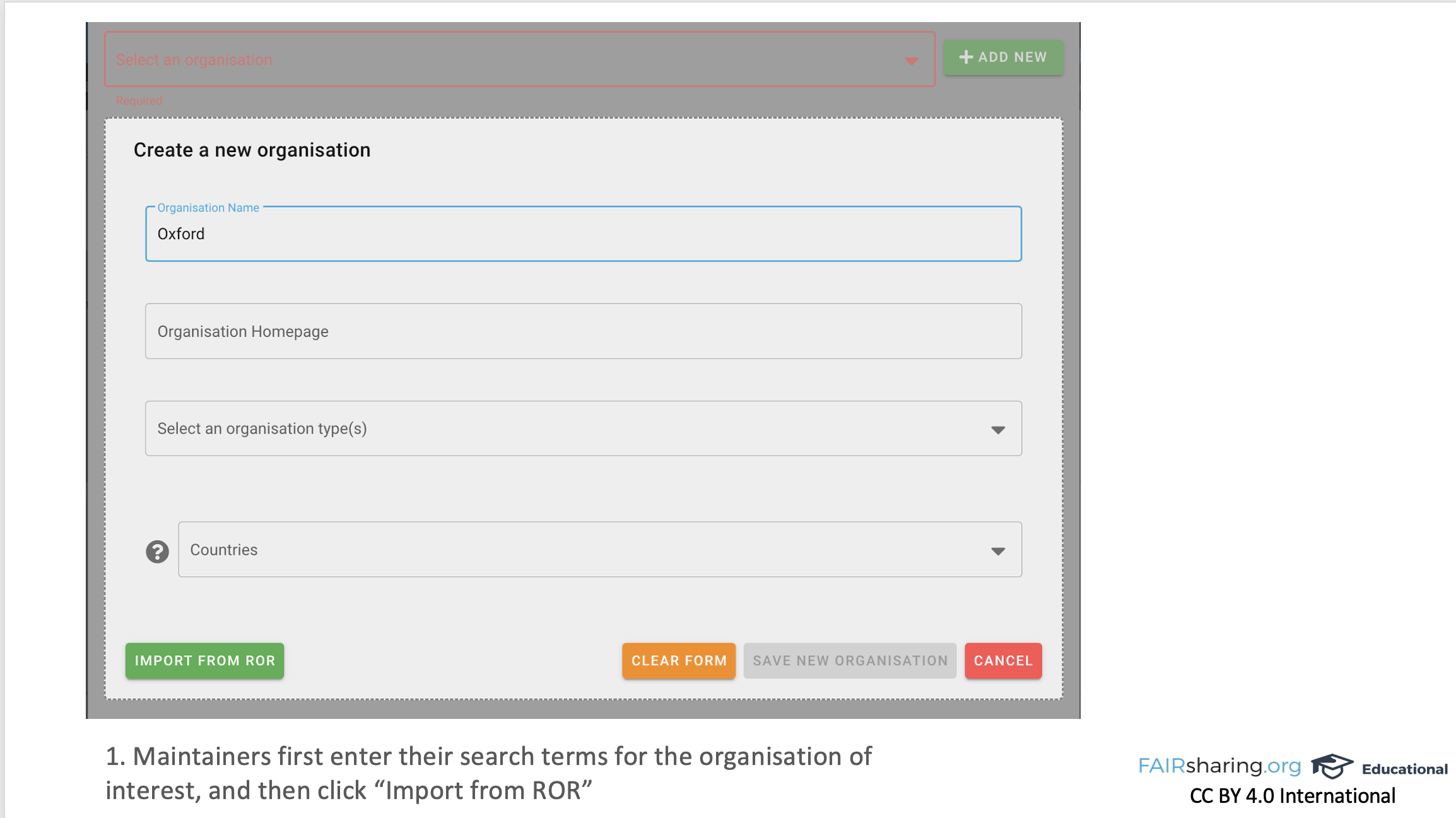
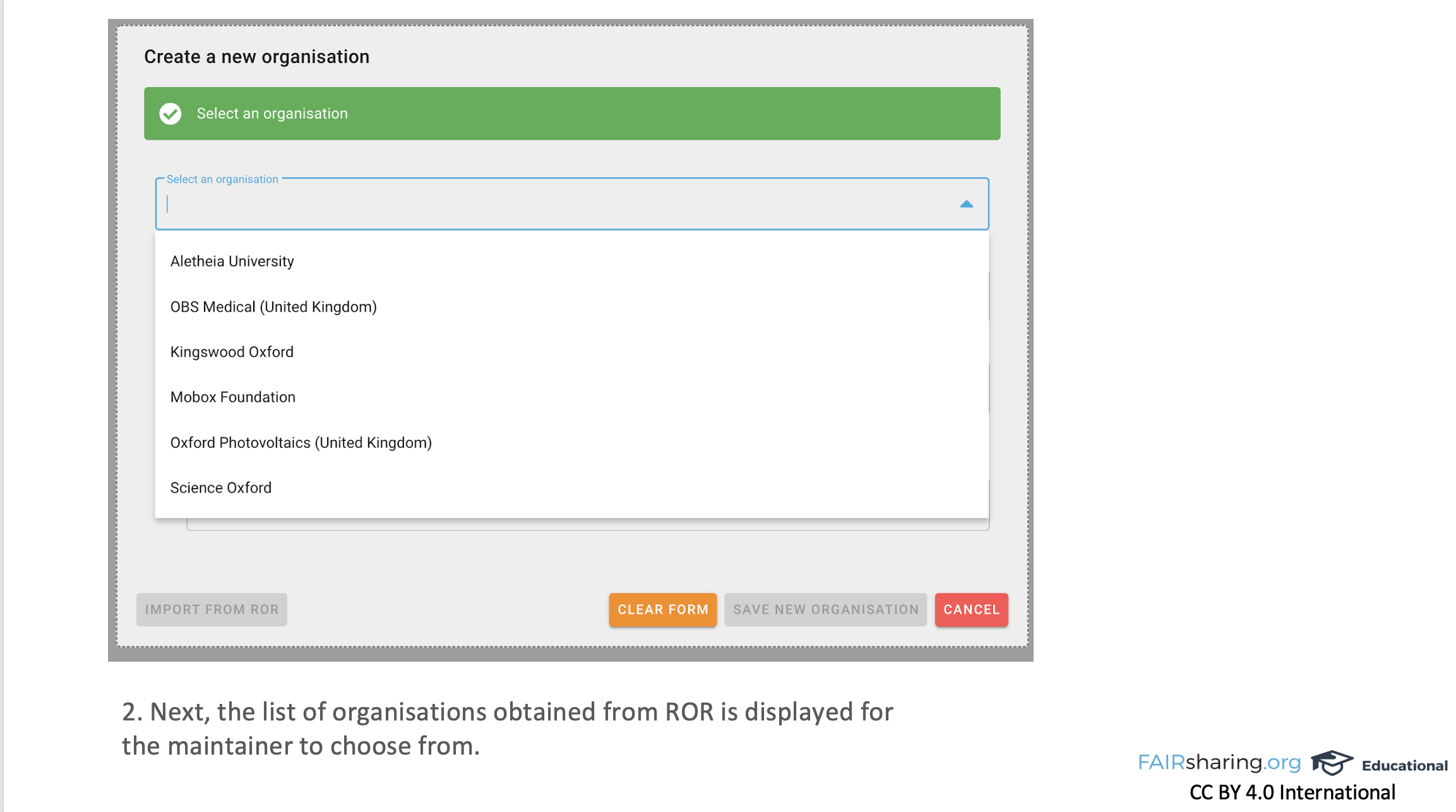
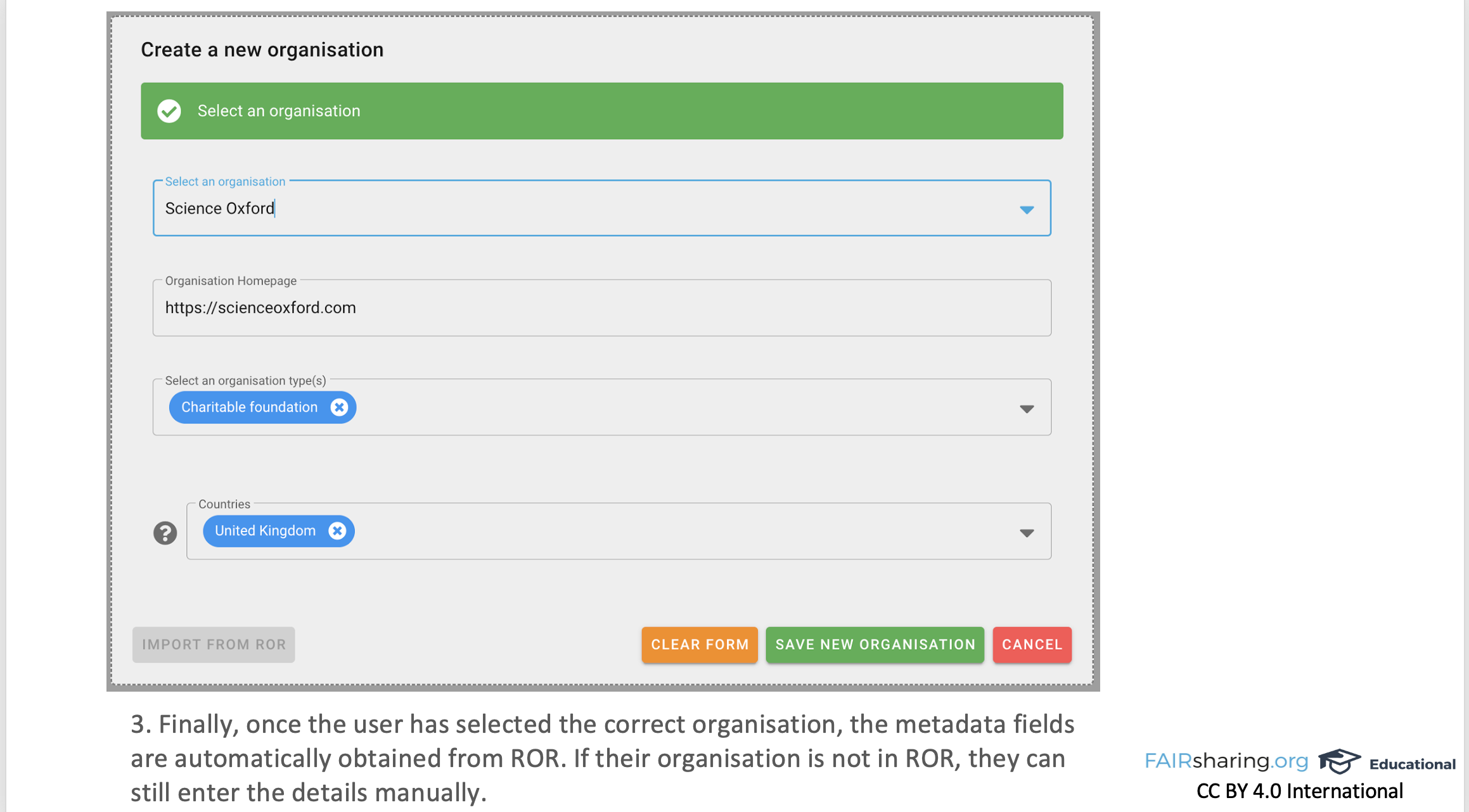
And so we were working from the bottom up, and so we ended up having to look in lots of different places. But for organizations, thankfully, it was more straightforward. We had a lot of organizations. Our definition of organization was quite deliberately loose. And so when we went to ROR, we couldn’t match everything, but it was still a useful match for what we did have. So not reinventing the wheel, using community terminologies, linking up with ORCID, linking up with ROR. FAIRsharing records can have maintainers. We also have our community curators, and both of these are the people who can edit records. So you either have to be the owner of the resource – a standard developer or a database developer or a policymaker – or you can be one of our domain experts that we’ve given particular roles and can edit multiple records. And they are trying to describe their resource in a way that is pertinent to them in their community. And so we try very hard not to put too many requirements on what they have. We provide fifty, at least, maybe sixty different metadata fields, but only something like three of them are required, because we understand that for each community, especially when we’re working cross-disciplinary, they’re going to have different needs for what they need to describe. But, saying that, we always like to have an organization. So even though it’s not a required field, we’ll come back to them and say “We’re not going to publish it till you put an organization in,” because we want to explore with them what they think of as an organization. So they can say that an organization maintains a resource, or collaborates on it, or funds it. A general “associated with,” if it’s sort of nebulous and they still want to include someone. Like often EOSC Life or EOSC will get an “associated with,” because your project is part of and supported by them, but it’s not a direct connection. And so we have a lot of different relationship types that link our records to our organizations. And so ROR being a large, open, community-driven database of organizations that has lots of different fields, and having relationships among the organizations, incorporating ROR into the new data model helps us speed up the creation of organizations in FAIRsharing for our users.
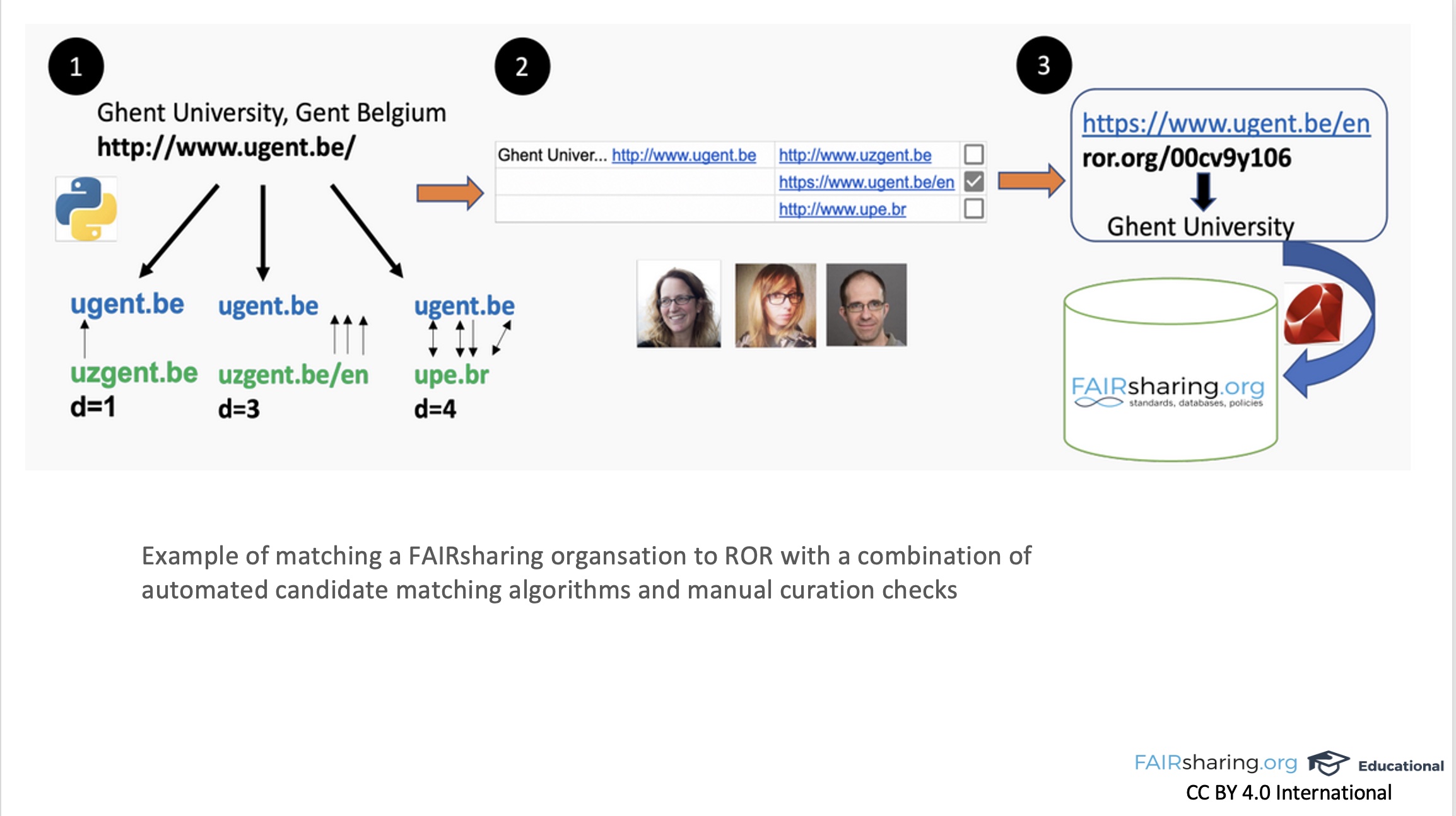
FAIRsharing doesn’t just allow them to search ROR while they’re making a record, but also provides the metadata from ROR for them so they don’t have to put it in themselves. So it’s a really nice way to ensure that we’re accurately describing what they need. Now in terms of direct implementation, what we did is – or I shouldn’t say, what “we” did. I helped, Ramon mainly did, and the rest of our curation team backed him up. So we have something like 3,500 organizations in FAIRsharing, which is nothing compared to, what is it? A hundred thousand [in ROR], or something like that?
Amanda French
About 104,000 right now.
Allyson Lister
A hundred and four thousand. Yes, and so clearly we’re not an organization registry, but people over the years have added many organizations. Ramon took our organizations and pulled the information from your API, and calculated an ’edit distance,’ so he looked at the name and the abbreviation and the home page fields for ROR and for FAIRsharing and he calculated the distance between the two terms for all of them, finding the least distance, the closest match. [*Note: More information is available in Ramon’s blog post about this work, and Ramon has made the scripts available in the ror-utilities GitHub repository.]
Amanda French
Right.
Allyson Lister
And then he provided a set of spreadsheets, where the majority have a cutoff distance. So if the edit distance was a certain value or or lower, then we didn’t really have to look at it and could discount them immediately. At the other end, there were a few hundred high-scoring matches that were very clearly matches. And then the curation team focused on those where the edit distance started moving away from optimal, but wasn’t so far away that it was clearly nonsense.
Amanda French
So this was a one-time process?
Allyson Lister
This was a one-time process, but now gets repeated on a smaller scale, I think it’s every three months. Because we always have new people adding organizations, and of course we encourage them to add organizations through the route we have with ROR. That means they should search ROR, because we have it built in, we have the connection to your API in our edit interface. But they don’t have to do that route when they put an organization in, and so every three months we run everything again, and we check all the new matches or any changed matches, and make sure they still make sense. So it’s still something that has to carry on, it will have to carry on for as long as we integrate with you, or we’ll just draw away over time.
Amanda French
That’s really fascinating, actually. And I love doing these interviews, because I’m always hearing about new ways to solve different problems. So first of all, that is one thing that we recommend, that nobody require the entry of a ROR into their system, because there certainly are institutions that are not in ROR that should be, or that are not in ROR because of scope issues, but that are in scope for your system. Oddly enough, you can require an organization without requiring a ROR ID, right, but you’re not even requiring organizations, correct?
Allyson Lister
We’re not, but we generally don’t allow it unless they put something in. So it’s a soft requirement, shall we say.
Amanda French
Yeah. But what is really interesting is what people do with those things that don’t match a ROR. I haven’t actually heard of anybody doing this kind of repetitive batch matching before. I know there may be other people doing it, but I think that’s really fascinating.
Allyson Lister
Thank you! Others seem to agree with you, as Ramon presented this work last fall at the Research Software Engineer Conference! If we’re going to integrate with somebody like ROR, we have to commit to it, you know. It was intensive at first, but mainly because of the creation of the original scripts and the batch of curation checks, as our records are all curated. But we’ve had a couple of these three-month checks since, and it’s been an hour or two maximum of checking, with the main curation team doing maybe fifteen minutes or so of checking each. So it’s not been a high overhead since then, and I think as long as you keep it up, you’re fine. But what we found is often that people can be overly verbose when they describe an organization, and they include, for instance, the name of the organization and all of the abbreviations in the same line and the same string, and maybe even the location, like a state and the country, or a city and the country. And they might use foreign language words. Some resources naturally have, as you know, working in ROR, multiple different names, depending on whether it’s in their native language, or in English, which they often add. And then home pages change over time, so sometimes the home page we have wasn’t the same as yours, even though the name was the same. Or sometimes the home page was the same, but one had an “https” and one had an “http,” or one had a “/home” and one had an “index.html.”
Amanda French
Yeah. Yep.
Allyson Lister
All of these different calculations. And so the automated procedure can only go so far because it will find a decent edit distance if there’s these ancillary changes, but ultimately the core is the same. So it’s interesting to really see how it works. And so, as of this month, Ramon’s given me some numbers: he says we have 3,462 organizations, and of those just over 1,500 are mapped to ROR, so we’re closing on 50%. But I don’t know if we’ll ever be going much higher than that. I think it’ll probably sit around that because of the scope issues. For us, 50% is not a “failure”.
Amanda French
I’m sort of interested in that: whether these are organizations that should be in ROR or whether it’s primarily a scope issue.
Allyson Lister
I don’t actually know. I’ve forgotten, do you include companies?
Amanda French
Yes. We do. The companies that we tend to include are companies that produce research, and that researchers will cite as their affiliated organization when they publish research. So because the primary use case of ROR is researcher affiliation – certainly not the only way that people use ROR at all, but the primary one – we include 3M and places like that, where people conduct and publish research affiliated with that company.
Allyson Lister
Yeah. So things like laboratories. A lot of people want to say that my group at this university is the one who made this, and so we allow those. Consortia. So with the International Virtual Observatory for astronomy. They make a lot of standards, and while not really an organization, they are the ones who are responsible for it. So we need to talk about them as an organization. And there are these programs that are part of the government, for example the Canada Vigilance Program which is related to the COVID-19 dashboard there. These programs are part of a government group or institute, but we allow them to self-identify. And so what we define as an organization becomes nebulous, or perhaps intentionally fuzzy. We said, “We’ll take all the ROR organizations that we want, but we’ll also have these other organizations outside of ROR’s scope, because this is how people want to provide attribution for resources.” And it’s a kind of personal decision. They feel, and I think rightly, tied to who owns a particular resource. And some will just put in their university, while others will put in the university and the department and the laboratory – all these different levels that they want to show. And so we try to be agnostic about what it is, and let them choose for themselves.
Amanda French
That makes total sense. And as you doubtless know, we inherited our seed data from GRID and have just begun curating the ROR registry independently in the spring of 2022, so we’ll see where it goes. Labs are in scope for ROR, but I suspect that we’re missing a lot of labs that would be in scope for ROR. And then for a lot of labs in a university, I mean, you know, there are sort of official ones, and then there are just sort of research groups that call themselves a lab that may not have an official existence.
Allyson Lister
Yeah. See, that’s interesting, because we didn’t get any matches with labs, so I presumed that the labs weren’t part of ROR. Interesting to know that that’s not necessarily the case.
Ah, yes, I see. So they are there, and they have the right parent organization. I mean, we’d be very happy to pull ROR IDs for laboratories. For example, the He Group: they are a really prolific ontology development group, and they’re heavily involved with the OBO Foundry which is a big life science and biomedical ontology community, and so they have loads of records. But that wasn’t a match in ROR. Maybe because they never submitted themselves? I don’t know. But we’d be very happy to have a ROR link for things like that. And those are the sorts of things that didn’t come up with matches. Whether or not they actually are in scope, and we just need better communication, perhaps.
Amanda French
That was the other thing I was going to ask, is whether you or anyone on the FAIRsharing team ever says, “Oh, let’s add this to ROR.” Not that that’s your job!
Allyson Lister
We have thought about it, and I think once or twice I did use the form. But it’s time, isn’t it. And when you are, as you and we both are, manually curated resources, you always have a pinch point of curation, which is one of the reasons we are building community curators. And no matter how hard you try, it’s difficult to keep up. Now, we have a commitment that we are trying to look at every record at least once a year, and together with our maintainers, who are meant to look at their records once a year, and the community curators, that’s our goal.
Amanda French
Right.
Allyson Lister
So I know that in that sense it’s hard for us, so if we don’t find the match but we’re not sure, or if we do find a match but there are metadata fields that don’t match, we tend to just keep ours, but add the ROR link. It could be that we have a more up to date web page, for instance, or sometimes it’s the other way around. And so that’s why we haven’t sort of en masse shunted all the metadata fields from ROR to FAIRsharing, because that would require another check. But there’s no reason why we couldn’t investigate sharing of some kind of the results of these three-monthly runs in sort of a more automated fashion. So if you had time to look at what we found and see where the differences are, we’d give you a list of differences. But I think for that we’d have to talk a little bit more about an official collaboration so we could say “This is what the goals are, this is what the end result will be.” Then something like the output of some of these regular runs might inform the curation you do, rather than having to go and fill out the form every time.
Amanda French
Oh, certainly, and our curation process is also new, and we have a nice community curation process as well, but we have a large volume of requests, even with just that single form, right. So we are doing wonderfully right now, but I don’t know that we have the capacity to do a lot of things. However, we have come across a number of these projects where they do have data about organizations. We do know that we want to examine or analyze it, but we just don’t have the capacity to do it. So you know, that does suggest a grant-funded project. But we are continuing to work on building a curation process that is really robust and scalable, and it would be great to try to create a sort of an abstractable way to do this with anyone who is adopting ROR. Because almost anybody who is adopting ROR has this issue. They have data about things that are not in ROR – maybe because they shouldn’t be, but maybe they should be. So we’re sort of just beginning to look at that. But we have one Curation Lead and something like half a dozen community curators, so we’re not looking for work right now. And I have to say we’ve had something like 1,500 curation requests this year. We get requests all the time, and they have to be evaluated and curated. We are proud of that, too, like you are, that these are well-curated records. We haven’t touched all of them, certainly, but we are doing a lot of curation. [*Note: in 2022 ROR added 2,010 new records and updated 10,073 records – about 10% of the registry – from external curation requests and internal quality assurance.]
Allyson Lister
You don’t have to explain to me. It’s the same issue with any curated resource, I think. My first job was with Swiss-Prot and TrEMBL; they’re now called UniProt, which is a protein sequence database. You’re coming from the library sciences, so you may not have come across them, but I was a biologist first, and then I moved into data science and I was a database programmer for them in Cambridge. Not the university, but an institute there. And they had a team of, probably, between the main group of curators in Cambridge and another group in Geneva, forty or fifty Ph.D.-level curators that were manually curating, and they could spend more than a week on one record, because they’d read all the publication material and could do extremely thorough curation. And there was simply no way they were going to keep up with all protein sequence submissions. A manually-curated resource is an amazing resource, but you’re always going to be fighting against scarcity.
Amanda French
I’ve done some work with, you know, crowdsourcing types of projects, and the ideal is to automate as much as you can, and to build tools that help the manual curators. If you have some kind of continuum between “everything is manually curated” and “everything is automatic,” my ideal for good quality metadata is that you automate as much as you can, and you build tools to help the human curators, and that produces to my mind the very best metadata. If you do only one or only the other, humans make mistakes, machines are very dumb and make mistakes, so you know, you really have to find that hybrid model that works well for everybody.
Allyson Lister
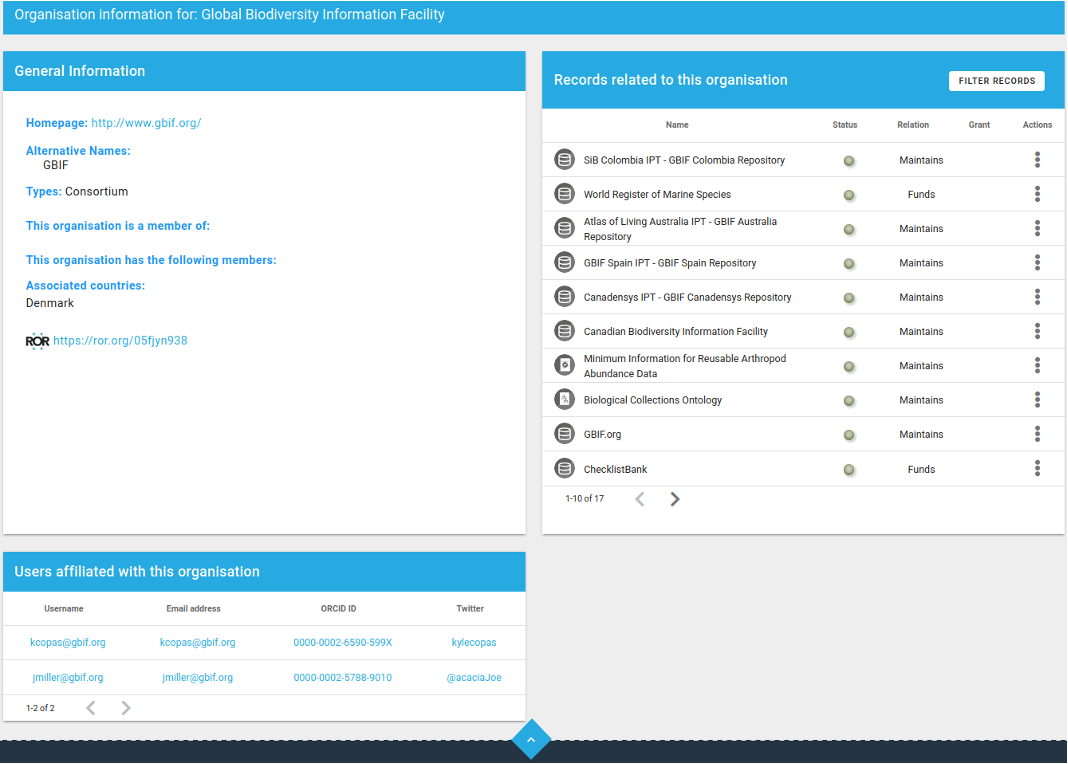
It’s true, because when we’re curating a resource, we have to look at all these different types of websites with all these different types of things. We can’t really screen scrape; it’s not really been an option. But with the advent of things like Bioschemas and schema.org, that kind of thing might happen in the future, but it’s not there yet. Certainly for our integrations, we look to automate as much as we can with checks, with curations like the ROR integration for organizations. Now is such an exciting time, because when we made the new data model, we wanted to think of an organization as a digital object. Before that it was the record, the description of the resource that was at the center of everything in FAIRsharing, and that’s still important to us. But we’re broadening our idea of what’s a node in our graph, if you see what I’m saying. There’s a graph for every single record in FAIRsharing. So you go to the Dryad record, you go to the ROR record, and you look at the graph, and it shows you all of its relationships that it has with all of the other resources that implement it, or the databases that share data with it. Hidden and not displayed yet, but still there in a graph, are the organizations, because the organizations themselves have their own digital object in FAIRsharing. And our next iteration of the graph will showcase that, so not only will you be able to see the resource landscape, you’ll see the resource landscape integrated with the organizations that develop and maintain and fund it. And if you look at our organization pages now, like the one for GBIF, you can see that we’ve put all the information there on its page.
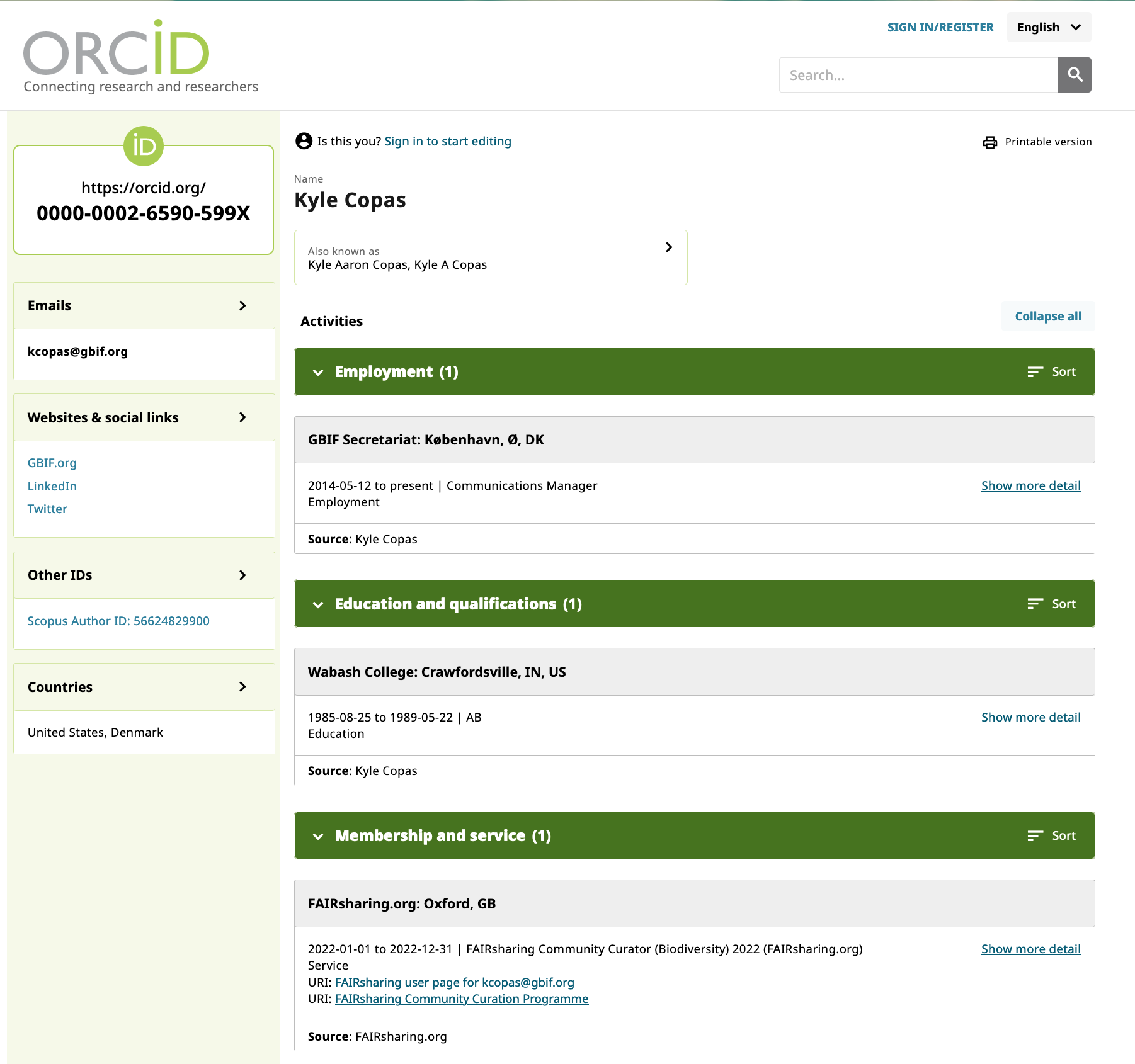
That’s our GBIF record. You can see that they sit as part of a larger ecosystem. So GBIF has seventeen records that it’s related to in some way, that it maintains, funds, anything. And it has its ROR ID and it has its country, because a lot of people like to find resources built in certain areas, and it has the users that are maintainers or community curators. In this case, there are community curators who are affiliated with the organization to broaden the scope of that graph. And then what you get from that is the ability to represent organizations as first-class citizens in FAIRsharing through relationships with people like ROR, and through the links they have to their resources, which are described in FAIRsharing. And our GBIF community curator Kyle Copas has particularly focused on the organizations within his consortium.
And so GBIF said, “Well, we are part of this BiCIKL consortium, and we need to find out, for instance, all the resources that are associated with our consortium members and if we’re missing anything. So how can we build a graph?” And Kyle said, “I know! FAIRsharing has graphs. But they’re not complete yet.” And he came to us and he became an early adopter. This was right at the very beginning of our community curator program. He’s one of the very first. And he used his expert knowledge to enrich the curation on our records related to his consortium. For him, it was the records and the relationships they had with their organizations that was most interesting. This is where it all ties back to ROR, and organizations as important members of an ecosystem of resources. As a community curator, he received attribution for his role with us on his ORCID profile.
His organization gained this enriched view of not just the resources, but the organizations that were relevant to their consortium. And they created a tool that uses our API. So essentially, Kyle came to us, curated with us, and then pulled all that data back out using our API. So it was a whole happy family of everyone getting what they wanted. Us getting high quality curation, them getting a view of all the organizations that were a member of the consortium, and the associated record curation, it was just a lovely collaboration. He began with a few months of quite concerted curation, and now he can move on to more of a maintenance mode. We’re looking for our community curators to get as much back from their role with us as we get from them. So this is the way in which we see organizations gaining the spotlight: through their relationship with the records that we store in FAIRsharing. And I want to show you the other way we show organizations, which is on our community curator pages.
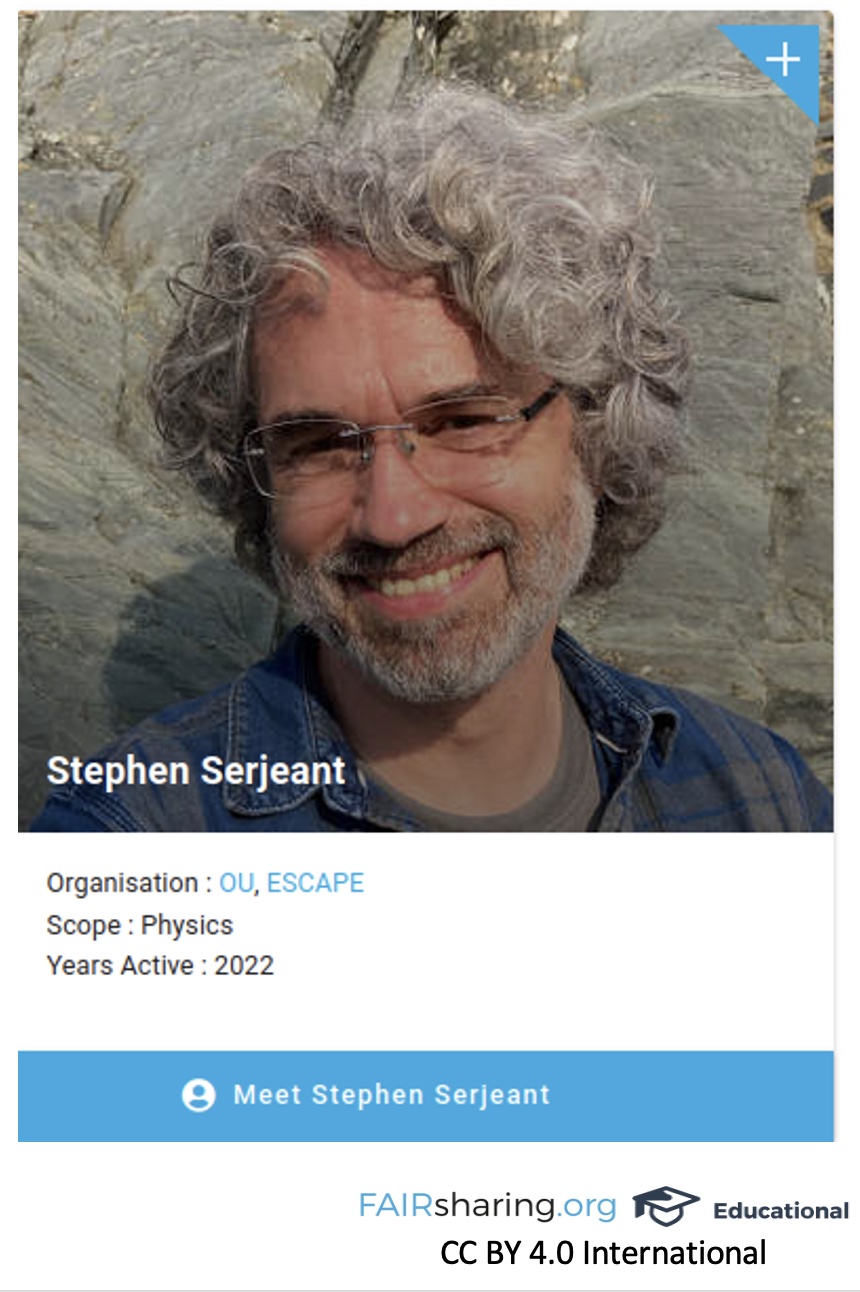
So Stephen Serjeant is from the Open University, and so we show that relationship. And we also have his infrastructure: ESCAPE is part of EOSC. And so it showcases their organizations as well as the community curator.
Amanda French
It’s a contribution in kind from those organizations.
Allyson Lister
Yes. So we want to make sure that they know they are valued, and make sure they’re getting something back. And it’s clear to their organization, as well as them, that they’re getting attribution. They’re getting expertise. Their curator pages show all the edits they’ve done. One of our curators has done something like eight or nine hundred edits. And she can add that information to her CV, and it has been automatically added by us to her ORCID profile. Back on her FAIRsharing profile, we can see how much work she’s done, we can see the organization she works for. And we invite them to write guest blog posts, and contribute to our educational material. This means that our community curators have a number of concrete points of attribution they can point to. We have a Slack workspace so they can chat with each other. We’re trying to build something that works for them as much as it does for us, because unfortunately what we can’t offer them is money.
Amanda French
Can I ask, do you have criteria for your community curators? Do they have to have a background in biological sciences or that kind of thing?
Allyson Lister
Only if it is biological science records that they want to update. The most important thing is a willingness to contribute. For example, Genveieve, one of our Humanities curators, began by curating humanities records. But then she realized that she actually also needed to update a related schema, a persistent identifier record we have. As a result, she’s gained that expertise. Now we ask that each curator self-identifies with a domain, and you can see that on their profile tiles. But they can edit any record in the registries, because those records are so heavily connected. We couldn’t just give them write access to one subject area, because there are too many links across disciplines. And so, although they have areas which they call their own, they can edit whatever they need to. Anything that gets edited goes into a queue to be checked out by our in-house curation team. So they don’t have to worry about making a horrible mistake. Because they’ve said that: “What if I make a mistake?”
Amanda French
That’s fascinating. I’ve done work with community transcription projects, because I actually come from the humanities as well.
Allyson Lister
Is that Project Gutenberg and things like that?
Amanda French
Like that, not Project Gutenberg itself, but other projects in the humanities and archives world. You know, there are all of these handwritten manuscripts that you just can’t OCR, you know. So I worked with Zooniverse and things like that.
Allyson Lister
Zooniverse! That is what Stephen, our curator from the Open University, is involved in.
Amanda French
Oh, really? Oh, I love Zooniverse. And Wikipedia too, I mean I’ve done things like that. But Zooniverse, I still am on their newsletter, and I had one project, and I’m always wishing that I had time to go and actually do transcription and give volunteer time to all of the projects on Zooniverse. It’s like when I retire, I’m going to be one of these people who spends all of my time classifying images and transcribing medieval documents and whatnot, you know, because it’s so fun, it really is.
Allyson Lister
I completely agree with you. I got distracted when I visited, because when Stephen said he would update the Zooniverse FAIRsharing record, I went to look on my own, and, oh no, I’m going to spend the next twenty minutes, when I should be working, navigating through all this! It was just too interesting.
Amanda French
Yeah, and the National Archives and the Smithsonian and the Library of Congress in the United States all have very fun crowdsourced transcription, crowdsourced classification things – they call it that, more than “curation,” you know. And then the New York Public Library, they had a whole collection of historic menus that they did a wonderful project on. They built a wonderful tool, and had a wonderful project for people to transcribe all of these historic menus. People ate a lot of oysters in the early twentieth century. You’d be surprised. Like, lots of oysters.
Allyson Lister
I was surprised at how black currants weren’t a thing in America, and then apparently, they were transmitting some disease back in the thirties or forties and so they had to all stop growing them, and then nobody wanted them decades later when they were allowed to grow them again.
Amanda French
I am so thrilled to know that! I actually watch a lot of British gardening TV, or did, and yes, black currants and red currants are always, you know, a sort of a staple plant in those programs, and you do not find those here at all.
Allyson Lister
You don’t get grape juice here. As a child you’re given black currant juice, that’s what you’re given all the time. Grape juice? Why would you have grape juice? You have to go look at the fancy juice area in the grocery store to find the grape juice. Isn’t it funny? Anyway.
Amanda French
Anyway. All right, back to ROR. I’m going to try to keep as much of that in the interview as I can.
Allyson Lister
You should definitely include the black currants. I went down a bit of a Wikipedia black hole when I suddenly realized everyone was black currant here, and no one was grape, and why weren’t we having black currants in the States. And so that’s why.
Amanda French
Yeah.
Allyson Lister
So, yes. The integration itself was smooth. Those challenges I mentioned, the fact that we had to do string comparisons, and the fact that we don’t have the same scope, those aren’t large challenges. Honestly, they’re just natural differences when you’re doing a bulk match against another repository. Compared to our match procedure of our database registry with re3data, or when we match to ORCIDs, the ROR integration was more straightforward. And so Ramon, who is a machine learning and natural languages sort of guy, he’s the person we go to anytime we want to do one of those things. So the first integration was just mapping from our organizations to yours, and a few months later we had the time to take a step further and integrate the search of ROR while someone is editing the record, which we wrote a blog post about.
Amanda French
Back when it was published I did read that.
Allyson Lister
And then the next step, which we’ve nearly finished, is the integration of the relationships, because from the very beginning in our data model, we allowed for a parent child relationship with organizations, because it only makes sense. But we hadn’t populated it yet, right? And so we were going to start by populating it every time a new organization is added. If it has a parent-child relationship in ROR, we’ll map that across when we map all the other metadata. Then we’ll look at our existing records and see where those parent-child relationships can be added as well.
Amanda French
Wonderful. So could you talk a little bit more about what benefits to you and your users the ROR implementation is providing?
Allyson Lister
Yes. Well, I mean clearly, before we integrated with you, it was much harder to ensure that we only had one copy of each organization, and so we definitely had cases where we would think we would have two resources, both developed by the same organization, but they actually had two different instances of the organization in our database. They were so similar, they would have been caught by something like integration with ROR, and they are being caught now. And so this sort of thing happens much less frequently. Access to a large, well-maintained resource helps with the creation and maintenance of organizations on our side. And having a higher-quality set of organizations has already helped our community curators, our maintainers, our consortium members, as they’re not stopped if there’s an issue with the organizations. Essentially, you can think of ROR not just as a database, but as a controlled vocabulary. You have a persistent identifier, and you have “label” and associated metadata. There’s no reason you couldn’t represent your organizations as a graph. And so it’s this kind of alignment with community registries and terminologies that helps anyone align with FAIR and enable FAIR data. And so when we use ROR, we are utilizing standardized formats, registries. We are also being interoperable. Whenever you have these persistent identifiers to identify digital objects in a repository, you are naturally making yourself more interoperable with other resources. You are also going to be really machine-readable: when you pull from the API, you don’t just get a string, “University of Oxford,” which doesn’t do much for those programs. But you do get a persistent identifier, and you gain machine-readability. So all these little things. Every time we take a step in that direction we’re enabling FAIR for us, but also for the consumers of our resource.
Amanda French
Fantastic. What would it help you if ROR did in the future?
Allyson Lister
Well, there’s a few things we already spoke about, one of which sounds like a lot of fun. If we had time and funds – which is where every sentence starts with these sorts of things – then being able to look at the differences in scope that we have and you have. Like we just discovered today, laboratories: you have them, but most of ours don’t match, and so knowing how we can feed back what should be relatively high-quality organizational metadata to you in a way that is, as you were saying, more partially computationally done rather than having to be done on a manual level. That is how we can help each other: we’re getting information from you, and anytime we have something that you may want, we give it to you. That’s one way of doing it. Again, that’s opening a can of worms in a way, because there’s so much we could do.
Amanda French
Absolutely. All right. Is there anything else you’d like to say before we wrap up?
Allyson Lister
Oh, I should mention that part of the reason we’re able to work so effectively with ROR and others is the collaborations that the Data Readiness group has within Oxford. Susanna’s role as the Academic Lead for Research Practice is also focused on ensuring that good practices around planning, executing, and reporting research are established and widely used across all divisions and groups at the University. Good research practices also include good research data management and FAIR data. The Bodleian Libraries also plays a key role in this activity, as do all libraries. So that is another way for ROR to reach out, because the libraries are often very much the focal point of these sort of concerted mechanisms for being FAIR and being open. It was our collaboration with Bodleian Libraries that gave us our route to mint DOIs, and to become a trusted organization with ORCID, so that we can push our community curator awards to ORCID. So I think that’s probably all I wanted to say. Thank you very much for having me and FAIRsharing!
Amanda French
Well, thank you so much for speaking to me. It was lovely to talk to you.
Questions? Want to be featured in a ROR case study? Contact support@ror.org.