One common question we receive about ROR registry records is whether they reflect organizational hierarchy and relationships between organizations – yes, they do! ROR does indeed support parent-child organizational hierarchies as well as other types of relationships between organizations. In this blog post, we go into more detail about how ROR supports relationships and hierarchies, how these are expressed in the metadata, how we curate them, and how users like you can explore and leverage this metadata.
Relationships in ROR at a glance
The ROR registry currently includes records for nearly 105,000 organizations (to be precise, 104,594 at the time of this writing). Across the entire ROR dataset, there are more than 22,000 total relationships between organizations (22,057), which means that approximately 21% of ROR records have at least one relationship to another record in the registry.
Parent-child hierarchies are the most common relationship type, with more than 17,000 instances. The most common scenario is that an organization has only one parent, but in some cases an organization has multiple parents (1,891 organizations, or about 1.8% of total records, have multiple parents). Several national-level and large-scale research organizations, such as the Czech Academy of Sciences (https://ror.org/053avzc18), have more than 100 of their child organizations enumerated in ROR.
Since its first independent release in March 2022 as part of the planned divergence from GRID, ROR has created over 1,000 new relationships between research organizations in the registry. We do this in collaboration with the global research community through our transparent curation process, and this service is entirely free of charge.
Relationships in the ROR data structure
ROR records store both structural and temporal connections in the relationships field. Connections and relationships between records can therefore be mapped and graphed. The relationship types supported are Parent, Child, Related, Successor, and Predecessor. An organization can have multiple relationships, but each relationship must be classified as only one of the above types.
The United States Department of Energy, for instance (https://ror.org/01bj3aw27), has many “child” organizations such as national research laboratories. Those child organizations themselves often have their own children representing different research units and funding bodies. Pictured below is a vertical “family tree” of the Department of Energy created from ROR records with an organization tree script showing DOE’s children and grandchildren (laterally related organizations are not shown in this view). This structure aligns with how the Department of Energy tracks both its research outputs and the research projects it has supported using ROR IDs and Crossref Funder Registry IDs.

List of US Department of Energy children and grandchildren expressed as items in an indented list from the ROR organization tree script written by Sandra Mierz.
Relationships are displayed on individual records in the ROR search UI, as for example the record for the US National Cancer Institute, whose parent is the National Institutes of Health (NIH) and which has multiple children and multiple related organizations.
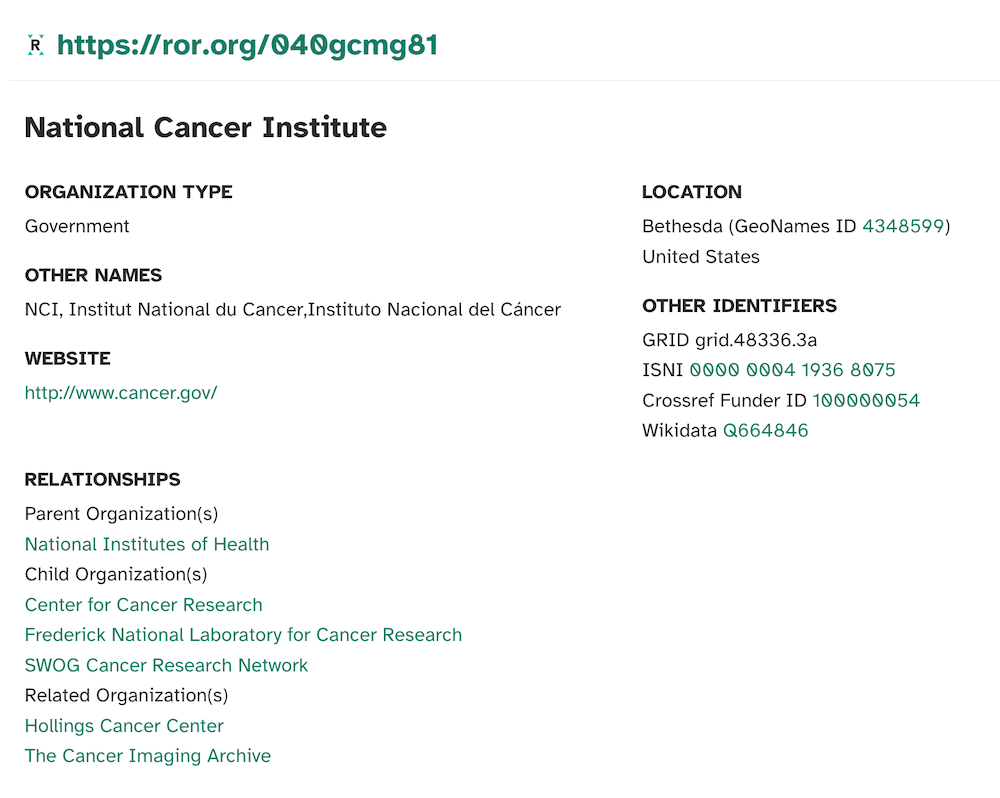
ROR record for the US National Cancer Institute showing the parent organization as the National Institutes of Health as well as three child organizations and two related organizations.
The relationships element in the ROR JSON schema is an array, so organizations can have multiple children, multiple parents, and multiple lateral relationships.

Relationships in the JSON of the ROR record for the U.S. National Cancer Institute.
If an organization ceases operations and passes on its work to another organization, that relationship is also reflected in ROR through the “Predecessor” or “Successor” relationship type. For instance, the Canadian Polar Commission has been succeeded by the Polar Knowledge Canada, and this is reflected in the relationship metadata.
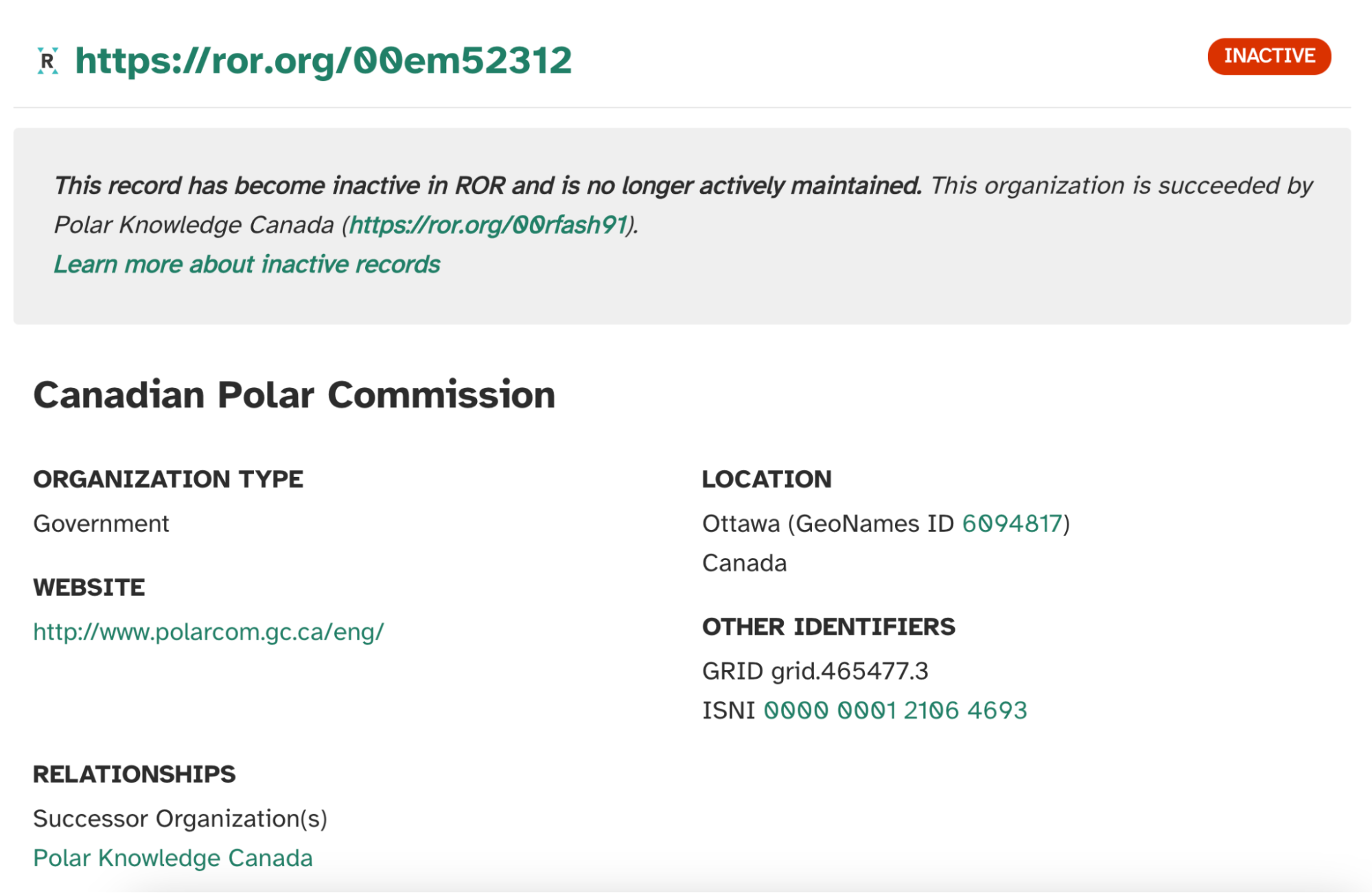
Inactive ROR record for the Canadian Polar Commission stating that the organization has been succeeded by Polar Knowledge Canada.
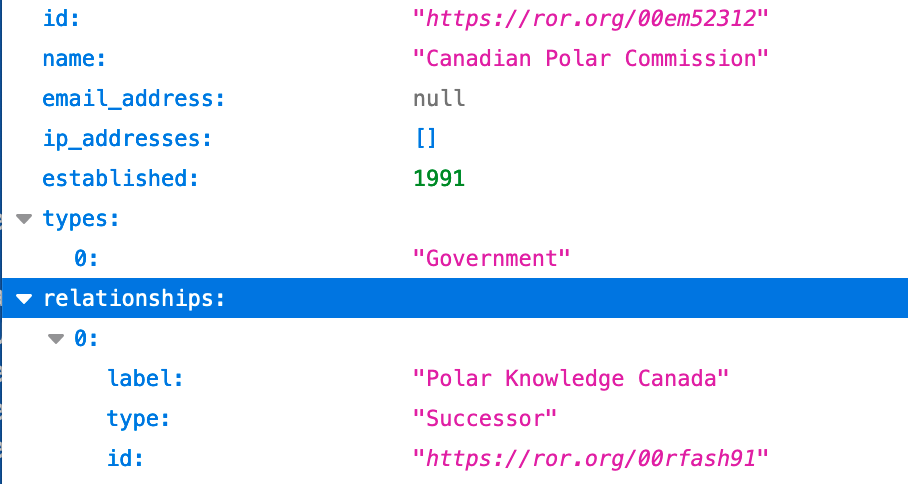
Metadata in the Canadian Polar Commission ROR record showing that the organization has been succeeded by Polar Knowledge Canada.
Curation policies and practices with relationships and hierarchies
ROR’s essential purpose is to connect research outputs to research organizations, and therefore it is not focused on capturing all subdivisions of a given organization, such as a university’s academic departments. The more granular the registry, the less suited it is to address the use case of tracking outputs at the institutional level. Likewise, large-scale reconciliation of research outputs, such as that done by OpenAlex to assign ROR IDs to millions upon millions of affiliation strings in their global academic graph, can become more difficult and time-consuming relative to the degree of depth. One of the things that users appreciate about ROR is that it provides a manageable level of granularity, which makes the dataset more immediately usable as well as easier to maintain than other sources of organizational data.
That being said, it is still important for the registry to be able to capture relationships and hierarchies between and within organizations. Through our curation process, we make careful determinations in consultation with the global research community about how to include and express these connections in ROR metadata. For example, when deciding whether a prospective child organization should be added to ROR or not, we consider factors such as whether it has an independent status/identity and funding sources from its parent organization, how the organization appears in affiliation usage, and whether a separate ROR ID for the organization would make the task of tracking outputs easier or more challenging.
As a global registry made freely and openly available for users and integrators around the world and maintained through a transparent community-based process, we also consider regional specificity in curation decisions involving relationships and hierarchies. This includes being aware of linguistic variations – for example, government agencies in many countries (Australia, Canada, and others) are called “departments,” which is not the same thing as a university “department” in some countries – as well as the specificity of local institutional structures, such as the unique nature of research institutes in France’s higher education system.
Another important aspect of ROR’s curation practices when it comes to relationships and hierarchies is optimizing ROR’s interoperability with other organization identifiers. ROR IDs map to other open identifiers such as ISNI, Wikidata, and Crossref Funder IDs. As part of ongoing work to reconcile as many ROR IDs as possible to these identifiers, we make decisions about adding certain child and related organizations that can help to optimize these mappings. This is particularly important in the case of the Crossref Funder Registry, which is expected to be incorporated into ROR in the future. Although we are proud that 90% of existing funding assertions in Crossref have been made with a Funder ID that already maps to a corresponding ROR record, we also understand the need to support the long tail of funding references and levels of hierarchy that are available in the Funder Registry, and we will continue to address this in the coming months.
Use cases and current integrations
ROR users can and do take advantage of relationships and hierarchies in ROR for a number of purposes, including but not limited to the following:
Large, complex institutions such as university systems and multinational companies and nonprofits want to track research outputs for the entire system as well as for each constituent organization.
Funders want to find all research outputs funded by the top-level agency or foundation as well as by subsidiary agencies and related research facilities.
National funders and Open Access programs want to monitor both national and institution-level adherence to Open Access policies.
Publishers want to manage institution-level subscriptions and Open Access agreements, each of which may include or exclude particular institutional subdivisions.
One example of a system that has cleverly integrated ROR to enable finding research outputs both from a single organization and from related organizations is The Lens, which offers large-scale search of patents and scholarly works. In December of 2022, The Lens announced that it had added a new ROR-based feature: a field in its structured search called “Institution ROR ID Lineage” that lets a user find all the scholarly works associated with an organization’s ROR ID plus all the scholarly works associated with that organization’s children. The Lens was already using ROR in its institutional data model, but this fascinating new feature shows an appreciation of what ROR’s relationships field can do. Searching by the ROR ID for the University of London (https://ror.org/04cw6st05) alone produces just over 98,000 results, whereas searching by the ROR ID lineage for the University of London produces over 780,000 results from the University of London and all of its 21 children.
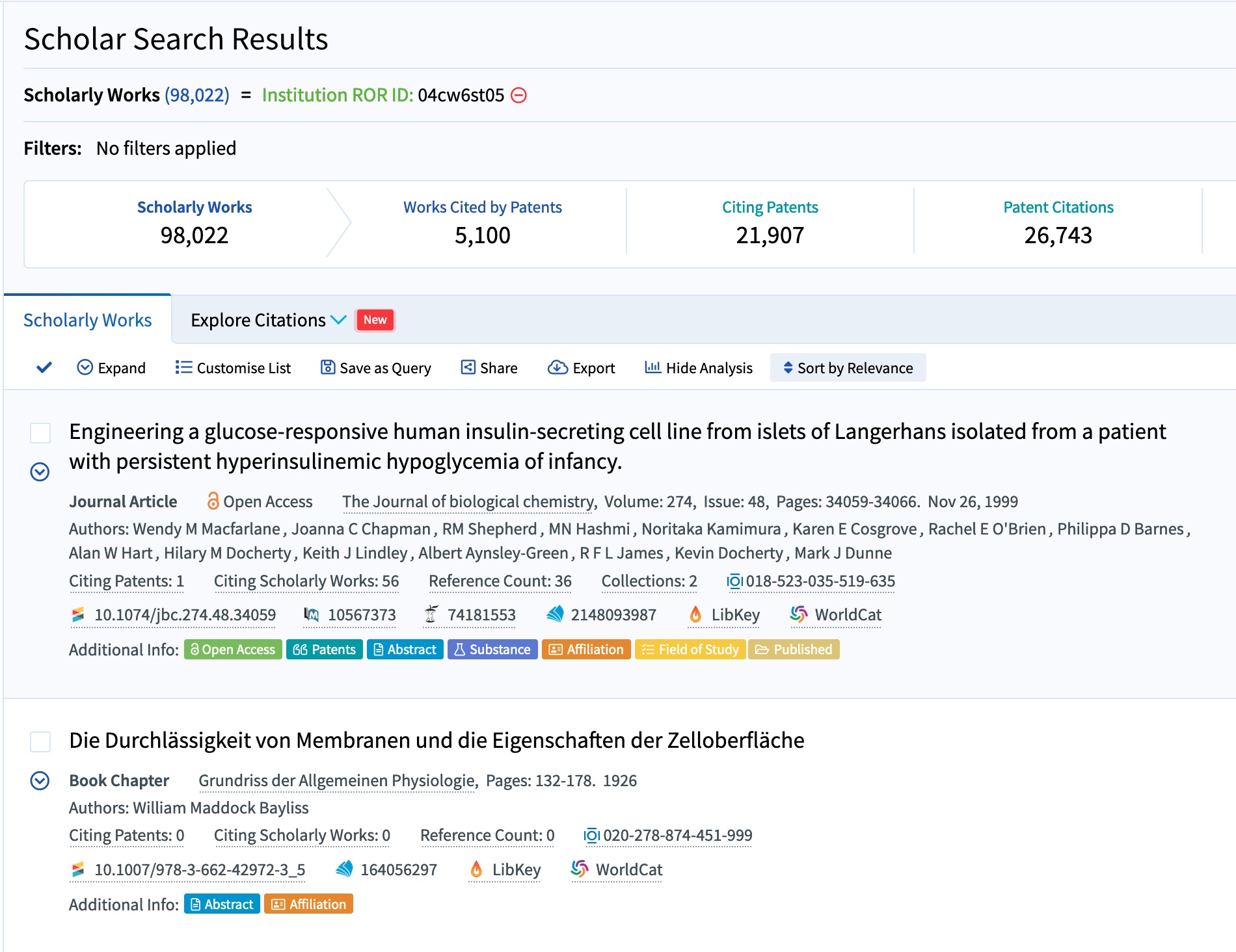
The Lens’s structured search for scholarly works by ROR ID showing over 98,000 works associated with the University of London alone.
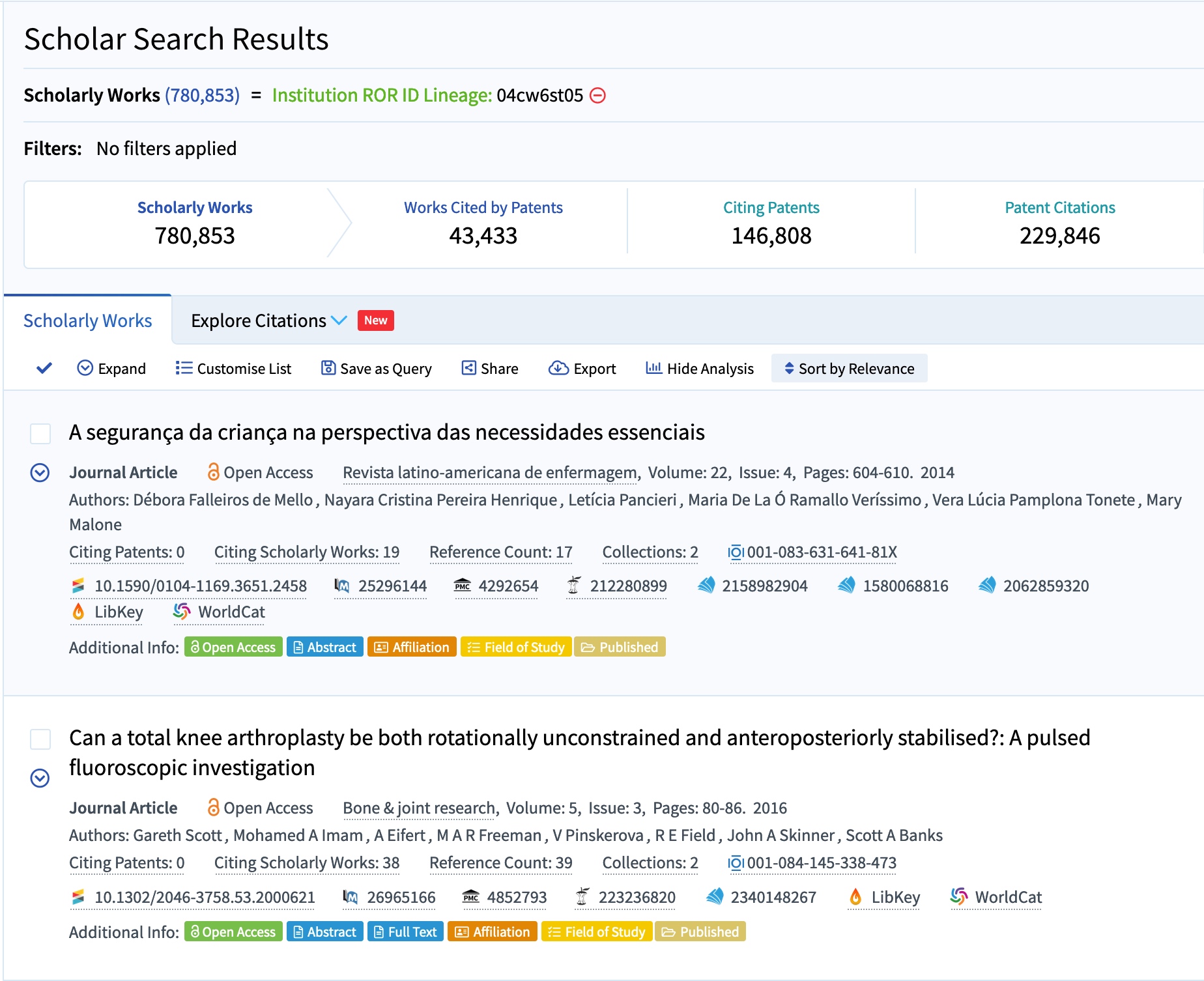
The Lens’s structured search for scholarly works by ROR ID showing over 780,000 works associated with the University of London and its subsidiary organizations. The Lens also offers the ability to filter results by sub-organization.
Germany’s Open Access Monitor, similarly, uses ROR’s hierarchies to allow its users to track open access data for large, complex German research organizations at the parent level, the child level, or in clusters of selected related organizations. The Max Planck Society, for instance, has nearly 100 subsidiary research organizations, and because the OA Monitor maps all the data it acquires from Dimensions, Scopus, and Web of Science to ROR IDs, it can give its users information about the open access compliance of all Max Planck Society organizations together, only one of them, or any combination of them.
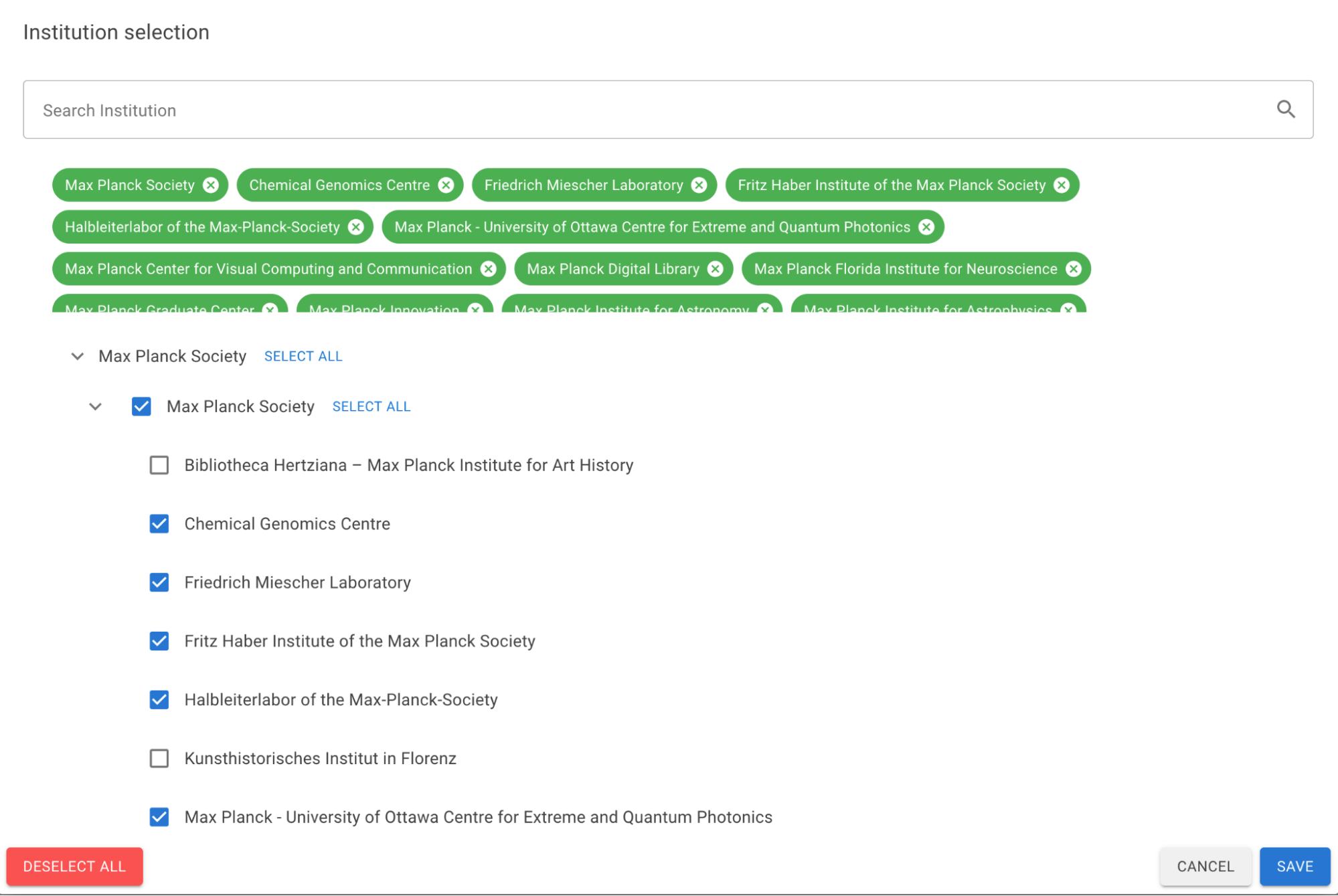
In Germany’s ROR-powered Open Access Monitor, a user can select all, one, or any set of the child research organizations of the Max Planck Society.
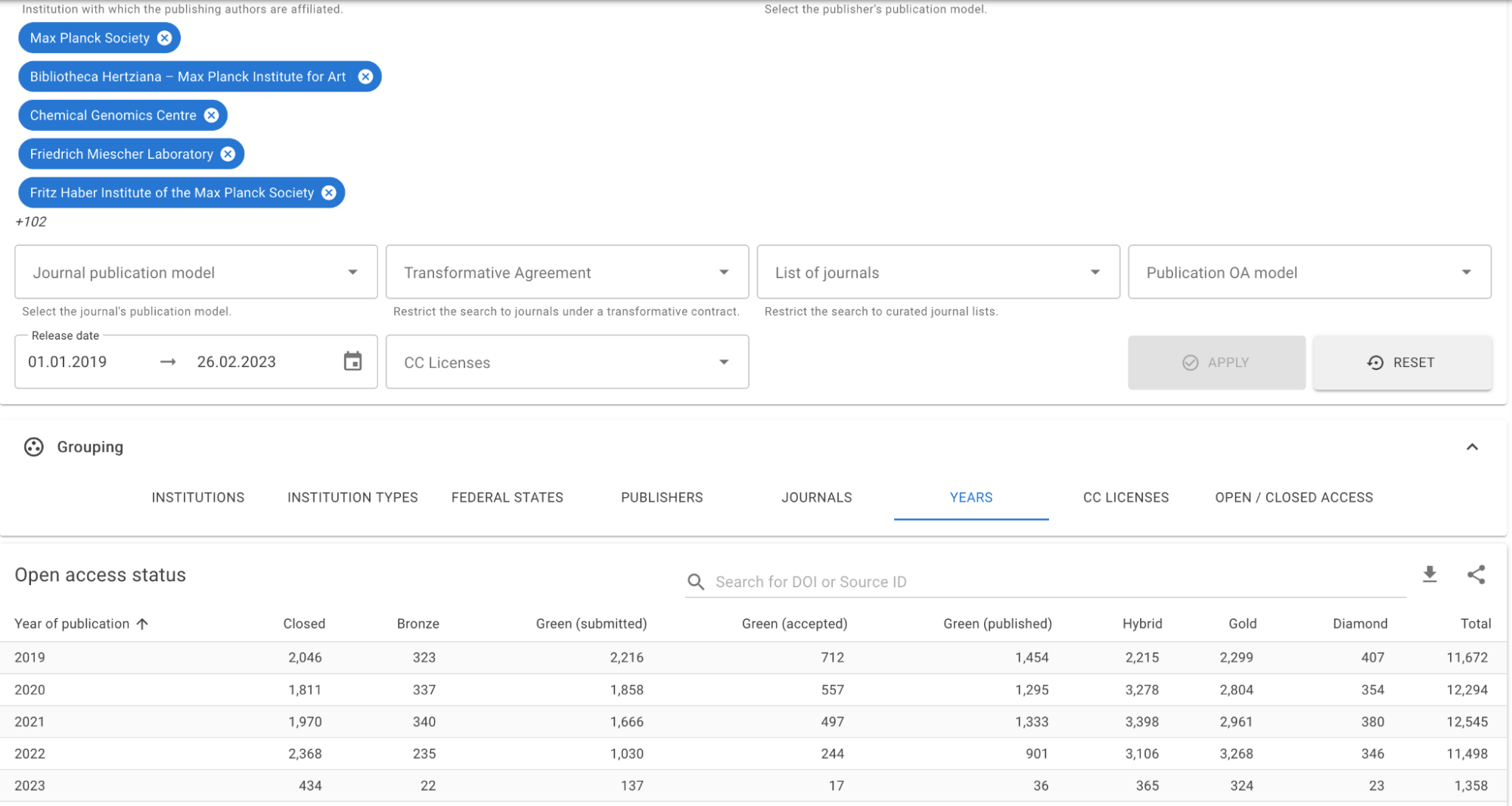
In Germany’s ROR-powered Open Access Monitor, a user who has selected all 102+ Max Planck Society organizations can see aggregate data on the number of publications in each Open Access category by year for the entirety of the Max Planck Society system. Users can also see the same data for any single Max Planck Society organization or any combination of Max Planck Society organizations.
Finally, we are hearing from a number of publishers who are interested in using ROR to manage open access publishing agreements with research organizations. Our favorite example of a publisher who is already using ROR for this purpose is Rockefeller University Press (RUP). In a recent OASPA/JISC webinar on publishing workflows, representatives of RUP explained and demonstrated several different ways in which they use ROR, including for the purpose of managing open access agreements. Their systems compare the ROR ID of the corresponding author’s affiliation to the ROR IDs for agreements, and when there is a match, the author is notified that their work falls under the terms of that agreement. RUP’s implementation shows the value of having ROR IDs incorporated in multiple parts of a publishing workflow and demonstrates that ROR’s degree of granularity is already more than sufficient to increase the efficiency of such workflows. Watch the full RUP presentation and/or the full webinar below:
We hope the preceding examples can serve as models for other projects that might use ROR’s relationships and hierarchies for similar purposes. If you too are using ROR’s relationships or hierarchies, we’d love to hear more about it – tell us more about your integration and we’ll feature you on our website, or get in touch via support@ror.org if you need help getting started.
Final takeaways
ROR’s support for relationships and hierarchies is specifically informed by our core use case of connecting research organizations to research outputs and motivated by our aim to provide an open and easy-to-use dataset with inclusive global coverage.
We hope this post has helped to provide more detail about how relationships and hierarchies are supported in ROR, how we make decisions about relationship structures in the curation process, and how this metadata is being leveraged by users and integrators.
To learn more, check out ROR’s technical documentation, and get in touch via support@ror.org with any questions. If you have feedback about relationship structures to add to or update in the registry, let us know via the curation request form.
This post was jointly written by members of the ROR core team: Adam Buttrick (Metadata Curation Lead), Amanda French (Technical Community Manager), Maria Gould (Project Lead), and Liz Krznarich (Technical Lead).
Feed
Categories
Archives
Tags
- adoption
- annual-meeting
- api
- aps
- caltechdata
- cambridge-university-press
- clarivate
- clear-skies
- coki
- communication
- community
- cris
- cross-post
- crossref
- curation
- curvenote
- data
- datacite
- datasalon
- development
- digicorepro
- digital-science
- discovery
- dryad
- earthscope-consortium
- europe-pmc
- facilities
- fairsharing
- feedback
- figshare
- funders
- governance
- grei
- grid
- guest-post
- hhmi
- hierarchy
- highwire-press
- implementation
- integrations
- interviews
- inveniordm
- janeway
- jobs
- latin-america
- machine-learning
- matching
- metadata
- metadata-game-changers
- mps
- mvr
- nwo
- oareport
- oaworks
- open-access
- open-infrastructure
- openalex
- optica
- orcid
- osf
- persistent-identifiers
- pidapalooza
- pids
- posi
- prototype
- publishing
- registry
- repositories
- requests
- research-integrity
- researchequals
- resources
- rockefeller-university-press
- rrid
- schema
- scholastica
- scilifelab
- scoss
- silverchair
- skgs
- steering-group
- straininfo
- sustainability
- symplectic-elements
- team
- usdot
- web-of-science
- working-group
- zenodo