Michael Parkin, data scientist at EMBL-EBI who helps maintain Europe PMC, explains why and how ROR helps with assessing funding impact and tracking researcher collaborations.
Key quotations
“As I mentioned, we can disseminate these ROR IDs, because we’ve added them to our own API. When you look at a grant record programmatically, you’ll see the ROR ID as part of that API response. And they are added to the Wellcome grant DOI metadata as well, so that’s another nice way of making this available to others. I’m a data scientist, so I love that. The more data the better. It’s great to have that kind of information so that people like me can come along afterwards and do some cool stuff that you wouldn’t be able to do otherwise.”
“For now, on the ROR community calls, it always cheers me up to see that bump in ROR IDs in Crossref metadata: ‘Oh, that’s the Wellcome grant DOIs we registered.’ Although I enjoy that, I really hope that in a couple of years that’s a tiny little blip because publishers have put so many ROR IDs in Crossref journal metadata that you can’t even see that on the graph. That would be really nice.”
“The way that you’re always inviting the community to provide feedback on things like schema changes, that’s excellent, partly because it lets people know what’s coming up, and lets you object if you have a strong opinion about that: ‘Oh no, that doesn’t work for us, have you considered that this might mess up this kind of system.’ I just think it’s a really nice way of doing things. But it is very hard to do and do well, and I think ROR does it very well.”
– Michael Parkin, Data Scientist, Content, EMBL-EBI
Amanda French
Hello! If you could, please start by telling us your name, title, and organization.
Michael Parkin
My name is Michael Parkin. I’m a data scientist at EMBL-EBI, the European Molecular Biology Laboratory’s European Bioinformatics Institute. I work on the Europe PMC team.
Amanda French
Can you tell us about the relationship between EMBL-EBI and Europe PMC?
Michael Parkin
There’s basically three levels. The parent organization is EMBL, the European Molecular Biology Laboratory. It’s headquartered in Heidelberg, Germany, and consists of six sites around Europe. There’s a big research center in Heidelberg, a synchrotron facility in Hamburg, a research institute outside of Rome, another one in Grenoble, and one in Barcelona. The sixth site is EMBL’s European Bioinformatics Institute (EMBL-EBI), based in the UK. All of these sites combine to make EMBL, which is a large, intergovernmental, not-for-profit organization, and Europe’s life sciences laboratory.
A lot of the EMBL organization is doing primary research and wet-lab work. Here in the UK, we are mostly on the data side of things. EMBL-EBI is split into two parts. Half of the organization runs data services and the other half is doing research, so some of my colleagues are bioinformaticians. I work in the services side, where we have many teams that look after life science databases, which are freely-accessible to anyone with an internet connection. For example, you run a research study that generates a lot of genomic data, and you want to put that data somewhere. EMBL-EBI will have a resource for that and an associated team that looks after it. Most of the teams manage these big biodata type resources.
My team is a little bit unusual because we are the literature team; literature is our data point. Our team maintains Europe PMC, which is a life science literature database. So there are a lot of similarities to the other kinds of big data that are stored at EMBL-EBI, but we’re a bit different because we’re focusing on the literature outputs rather than the data outputs that are generated by research. We are funded by EMBL itself, as well as 37 other funding organizations, mostly in the UK, but also across Europe and more globally.
Amanda French
The volume of scholarly literature today makes it essentially big data.
Michael Parkin
Yeah, it’s gotten increasingly bigger over time. The biggest data source at Europe PMC is PubMed. We have a faithful copy of everything that’s in PubMed. That’s approaching 40 million abstracts, in the mid-30s at the moment. And really the genesis of Europe PMC was around collaboration and data sharing with the NCBI, the National Center for Biotechnology Information, which hosts PubMed and PubMed Central, a database for full-text copies of journal articles. I think there’s over 7 million of those. So EMBL-EBI is really well positioned. We have a lot of computer power and data storage, either on site here outside of Cambridge or within the UK. And the volume is significant. So it does fit well within the scope of these databases, and one of the nice things, of course, is they’re all public access. It’s just kind of really a nice thing. The idea is that it’s for the research community. And so at the core, this is a public good.
Amanda French
Wonderful. When and where did you personally first hear about ROR?
Michael Parkin
I started at EMBL-EBI in 2016, and a couple of years into my time here I was getting interested in PIDs, and there was the opportunity to go to the PIDapalooza Conference. I went to the one in Girona in 2018, and I remember there was an open session, and I think it was someone from Crossref who gave a talk to say “watch this space” in terms of organizational identifiers. I don’t think the name “ROR” had been chosen at that point. There were actually many presentations at PIDapalooza 2018 about organization identifiers, whether from a librarian’s perspective or publisher’s. But I think there was just a few minutes’ long talk to say that Crossref and ORCID were working on organization identifiers.
Amanda French
You are in fact correct! I was not there, but having studied the history of ROR, I know a great deal of the technical work that did become ROR shortly thereafter was going on then. ROR’s official launch date is January 1st, 2019, and it was the Crossref technical team that really did a lot of that work to stand that up. So I’m perfectly certain that in 2018 they were working on it, and I do think the ROR name was chosen in late 2018 or something like that.
Michael Parkin
I feel like I would have remembered some lions!
Amanda French
You’re talking about the pre-lion period!
Michael Parkin
There were a lot of talks at the conference about the use of organizational IDs, and the idea of something coming from organizations like Crossref and ORCID, who we know a lot about and often collaborate with, was a really cool thing. I was kind of interested to see where it went, so I guess that that’s where I first heard about what became ROR. Perhaps that was the first announcement to the public.
Amanda French
Well, there were working groups from 2016 to 2018, really about three years of discussions and working groups and plans to try to stand it up, and then the official launch in 2019. And now here we are! Who were the primary advocates of implementing ROR at Europe PMC?
Michael Parkin
There are two main angles to this. As I mentioned, Europe PMC is funded by funders of life science research, and funders typically have a strong desire to track the outputs of their funding. They want to see the impact their funding has. And one aspect of that is to look at journal publications. That’s often the way scientists communicate their results, and those results are an outcome of the funding that they were awarded by a particular grant. Part of the puzzle of that is, “Well, which institutions does this funding go to?” That’s a key thing to keep track of, and it gets very, very difficult to track when affiliations in publications are captured just as strings of text; it’s very messy. So there’s a desire from our funders that Europe PMC has some way of disambiguating institution names as a piece of the impact assessment puzzle. That’s one of the reasons we want to be able to do closer inspection of institutions via IDs.
The other side is that EMBL, the organization that we’re a part of, produces a lot of its own research, and EMBL wants to know where EMBL-associated researchers are publishing, and especially, who are they collaborating with? That’s a really key thing for us. It’s, “Where are the networks between EMBL researchers and other institutions around the world?” And again, one way that gets measured is by looking at journal articles, finding which ones have been published by groups in our organization and the other institutions they worked with. Again, really hard to do when these affiliations are just strings of text. So there’s also a desire from our organizational side, to be able to have better information about which institutions are which, and making networks and cross-connections between the two. We do a lot of that with ORCID, and we want to do the same with ROR and institutions. Those are the two key drivers, one side for the funders for research impact assessment, and one from our own organization, knowing who’s doing the research and where the collaborations are. Those have been the main use cases for us.
Amanda French
Wonderful. I’m going to ask a follow-up question, because I have heard from others that they are particularly interested in this collaboration question, finding out who their researchers are collaborating with. Why is that an important thing that people want to know? What are you going to do with that information once you can find it out?
Michael Parkin
I don’t know too much about the details, because our team generates the data for others at EMBL to digest, and EMBL uses this information in a number of ways. But essentially, it showcases the collaborative nature of our work to our funders. EMBL helps to create links and connections between different research areas in the life sciences, so being able to show the number, scale and scope of our collaborations is one way of demonstrating our impact. I think that’s where EMBL sees this collaboration information as being valuable.
Amanda French
That’s helpful, actually. It’s something that I’ve heard some people who are implementing ROR say, that that’s part of why they’ve implemented ROR, is to track research collaborations. Universities want to track their own institution’s output, which is surprisingly difficult, but they also want to know who their researchers are collaborating with. So I think it’s similar to what you’re talking about: Are our researchers in this American institution collaborating only with European researchers? Or are they, you know, really taking a global view and collaborating as much as they could be or should be with researchers in Asia or researchers in South America. My sense is that that’s why they want to know that.
Michael Parkin
I expect these collaborations are usually not something individual researchers worry about too much. But at the higher strategic level this becomes an important question to address. Maybe eventually it does feed down to the researchers, and it will steer the collaborations: “Well, you know, we’re not really doing a lot of work with, say, South America, maybe some project around there or some collaborative network would be good.” Publications being just one thing – it helps you see whether that collaboration is fruitful or not.
Amanda French
Describe for us what you’ve done with ROR at Europe PMC. I think you’ve done several things, actually.
Michael Parkin
I’ll talk more about the more recent one. But the initial work we did, which is already listed on the ROR website, was part of a European Commission-funded project called FREYA, which was a successor to the THOR project. They’re committed to Norse mythology! The FREYA project was all about PIDs and PID interconnectivity, and as part of that we were looking at publications. It’s important to mention that in Europe PMC we have our publications world, which is most of what we do, and we also have the grants world, which is exclusively for the Europe PMC funders. I’ll just make that distinction now, because I’ll talk more about the grants side of things.
But the initial work we did with ROR was on the publication side of things, and it was exactly this idea that our organization, EMBL, wanted to have publication data about EMBL sites, how many papers they were publishing and which organizations they were collaborating with. We had a fantastic intern on the team at the time who built a machine learning model that would look at the affiliations in publications and pick out ones that had an EMBL site affiliation on them. As I mentioned, there’s a few of them around Europe, the sites outside of Rome, in Grenoble, in Heidelberg, in Hamburg, and luckily there’s a ROR ID for each of those, which is fortunate, because I can assign papers to individual institution locations.
Amanda French
And if there weren’t a ROR ID, you could request one.
Michael Parkin
That was one of our initial questions, and I think it’s a question you get a lot, “What is the hierarchical structure?” Because you can go down to the department level of a university, say, and get really granular. For us in EMBL, each site has its own ROR ID, which is very beneficial, but they’re also written fairly similarly. They all have the words “European Molecular Biology Laboratory” in the name, and then you’re looking for basically which city it’s in. So that was the specific project: building this machine learning model that can look at affiliations in articles and pull out the ones that are from our wider organization, and then we can track things like collaborations with other countries. That was a key part of what the strategic team here wanted to do. That wasn’t my work at all, and I don’t take any credit.
The project I’ve been working on more recently was in our grants world. Moving away from the publications, where there are forty-something million records, to the grants world, where it’s much smaller: there are about 70 to 80 thousand grants. It’s a lot more manageable. And so what we’ve been doing is attaching ROR IDs to the institutions that were funded by grants from the Europe PMC funders. Our grant data looks not too dissimilar from a journal article, really. It’s got a title. It’s got an abstract. It’s got a person associated with it, but instead of being an author, we call them PIs, principal investigators, and they are attached to an affiliation of some type. Usually it’s the university, but it can be companies, or it can be charities. I recently saw one that was a cathedral. It’s a real spread of places these PIs can be at.
Amanda French
Yes! I happened to see the ROR ID for York Minster the other day, which is the enormous cathedral in York.
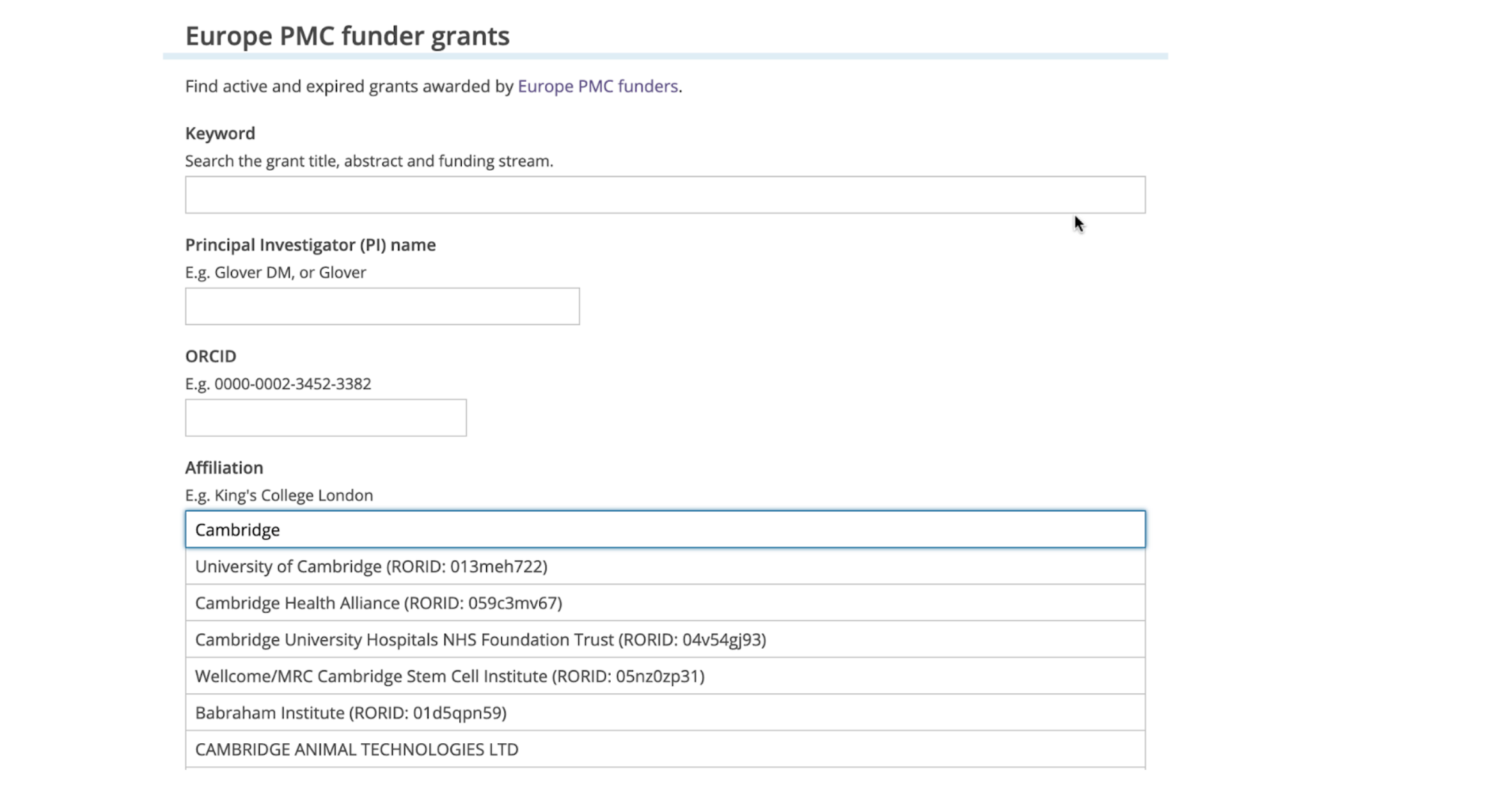
So there’s a real spread of organizations, and the data comes to us through spreadsheets. Some of our funders are relatively small organizations, perhaps with a small number of staff, and anything overly technical is not going to be fit for purpose. We have a spreadsheet where they can fill out all the grant details, and one of the columns of the spreadsheet is the organization that the PI is at, and over the last decade and a half, there’s been a lot of variation in the way that those affiliations get listed. We’ve had the University of Cambridge spelled in about eight different ways, with those including lowercase, uppercase, commas in different places. On our system, if you type “Cambridge,” into the auto-complete menu, you get six or seven variations of “Cambridge University,” so “the University of Cambridge,” “Cambridge, comma, University.” It’s terrible.
So what we were looking for is a way to normalize those. This is probably a very classic use case of ROR here. We’ve wanted to do this for a very long time, actually. This is not a new problem. It gets increasingly worse as time goes by and funders find new ways to write different names for universities and such. We wanted to combine these all, and attaching these affiliations to a ROR ID is a really, really neat way of doing it. On the one hand we get a PID, which is wonderful, something we can share with others and disseminate. But also you have a very well curated registry, which happens to provide a suitable single affiliation name. I think it’s called the primary name in ROR, but we call it internally the “official” name. And, as you know, the ROR registry gets updated. I imagine if some university decides “Actually, I prefer if you use the Spanish spelling of our name,” that would be updated, and we’d incorporate that into our system.
Selecting an affiliation based on ROR integration in Europe PMC Grant Finder
What we’ve been working on is taking our very, very long list of institution names in Europe PMC grant data, many of which are copies of the same institute, just spelled differently, and matching them to ROR IDs. We use the ROR API to do that. We have our machine learning model for publications, but the grant data is a little different. It’s a little bit more straightforward, actually, because these institution text strings tend to just be the institution name, whereas in publications you get postcodes, countries, cities… Sometimes you get two affiliations merged together in the same bit of text. Luckily for us, with Europe PMC grant data, it’s usually just something as simple as “the University of Cambridge”.
So we basically took all institution names, ran them through the ROR API, and had a threshold for matching. The ROR API, beautifully, gives you a score. It tells you how it matched, what kind of similarity was used. We came up with a threshold where “Anything below this, we’re just going to leave this.” We never had the intention that we’d get 100% coverage, because although you do have York Minster, for example, in the ROR registry, we didn’t expect everything to be there. I was actually very surprised at how many companies appeared in the ROR registry. I wasn’t expecting that, but there are many companies that do research and receive external funding.
Amanda French
I was surprised by that as well when I first came to ROR. I was like, “Wow, there are a lot of companies,” you know, and I’d see one and say, “I’ve never heard of this company,” and then I’d Google them and discover “Oh, yes, they do actually do quite a bit of research.” Especially pharmaceutical research, biomedical research. There are lots of small companies, as well as large companies.
Michael Parkin
We knew there’d be some things that we would never expect to be in ROR, so we never went in with an idea that we need to make sure that every single institution we have has a ROR ID associated with it. That just seemed wildly optimistic. And so as we went through this process, we did check everything manually. That was kind of inevitable, that we’d need to do some sort of manual step.
Amanda French
And what kind of volume are we talking about here?
Michael Parkin
I think there’s about 4,000 ROR IDs that we added, so that’s quite a bit. A reasonable amount of checking. I did it over several days to not burn my brain out. But we prioritized institutions that came up a lot in our grants data, and I think I’m right that the top institution was the University of Oxford. That was the most frequently occurring institution I think that was linked to several hundred grants, something like four or five hundred grants just from the University of Oxford, so actually a reasonable percentage of the total. We went from the top down, looking at how many grants are associated with each institution and prioritizing assigning a ROR ID to the top ones, because there are an awful lot of institutions that just appear once. We tried to get as much coverage as we could for as little time investment as possible. But over time we will revisit this kind of exercise. This isn’t an automated process. It was a kind of one-off task. We’ll revisit it, and try to bolster our ROR coverage.
But what we’re hopeful for, and I’m even more hopeful on the publication side of things, is to get funders to provide us with the ROR IDs. One funder does, which is wonderful, actually, that they go to the trouble on their end of figuring out the ROR IDs for these institutions that they’re funding, and then they pass those to us. But we don’t make that a requirement, because as I mentioned, some of these funders are small, and that’s a large burden. We really want their grant data, so we don’t require the ROR ID. In fact, we don’t mandate a lot of grant metadata, to try and make it as simple as possible.
Amanda French
We recommend that people don’t require ROR IDs actually, because sometimes there are organizations which are entirely legitimate for your use case, but are out of scope for ROR, or there are organizations that are in scope for ROR, but happen not to be in it yet. And while we do have a quite robust update mechanism right now, it still can be weeks before something gets in which is not always congruent with people’s timelines for what they need to do.
Michael Parkin
We ask for ORCIDs as well. They are relatively well used, I think. At least one of our funders mandates ORCIDs for their funded researchers.
Amanda French
It makes more sense to me to mandate ORCIDs, because it’s really not that difficult for an individual to just go sign up for one, whereas because ROR is curated, you’re reliant on somebody else to create that for you.
Michael Parkin
Yes. It would be nice if all the funders were providing this data to us at the point the grant enters our system. Then we’d never have to do this process. We’d just take those ROR IDs and add them to the system. But that’s not practical, so this was kind of a jump start. We went from around 10% of institutions in our dataset having a ROR ID, to about 80%. That’s a nice boost.
And as I mentioned, we can disseminate these ROR IDs, because we’ve added them to our own API. When you look at a grant record programmatically, you’ll see the ROR ID as part of that API response. And as you’ve mentioned in your talks, they go into the Wellcome grant DOI metadata as well, so that’s another nice way of making this available to others. I’m a data scientist, so I love that. The more data the better. It’s great to have that kind of information so that people like me can come along afterwards and do some cool stuff that you wouldn’t be able to do otherwise, or that would certainly be a lot more arduous when you have to sift through eight different variations of “the University of Cambridge” and somehow figure out that those are all the same.
Amanda French
And do that for 4,000 institutions.
Michael Parkin
It’s a punishing task for everyone to do that themselves. It makes much more sense for an organization to take responsibility for doing that, and then you can share those results with everyone. So that’s the grants integration. That’s quite different from the publications one, but the latter is ultimately where we want to be, because that’s the main data at Europe PMC – journal articles and preprints and other associated literature. I’m just really hoping that although maybe publishers don’t benefit hugely from putting ROR IDs in their journal workflows, it is extremely useful for everyone else who comes afterwards, including our team, but also for funders, for instance, it would be immensely useful. I know there are a few publishers already doing this. I think eLife and Hindawi at least.
Amanda French
Yep.
Michael Parkin
Europe PMC gets a lot of full-text XML files from PubMed Central. I’d love to see ROR IDs captured in those full-text documents, because then we can reliably start pulling them out. Both of these sorts of initiatives I’ve described are one-off tasks in which we were manually adding a ROR ID to something that already existed. I’d really love to see these pipelines automatically pulling these PIDs in. But it relies on the publisher or the funder to do the work. Because it is work, adding these ROR IDs to your system.
Amanda French
Absolutely. And I think there’s a lot of momentum in that regard. I think if we talk a year from now, there will be a much greater percentage of those publications that have ROR in their data. We know of a lot of service providers who are adding ROR and publishers who are adding ROR. And we would love to see PubMed’s systems officially support ROR.
Michael Parkin
PubMed has supported ORCIDs for quite a few years now. For now, on the ROR community calls, it always cheers me up to see that bump in ROR IDs in Crossref metadata: “Oh, that’s the Wellcome grant DOIs we registered.” Although I enjoy that, I really hope that in a couple of years that’s a tiny little blip because publishers have put so many ROR IDs in Crossref journal metadata that you can’t even see that on the graph. That would be really nice. I’ll be a little bit sad, because once upon a time, you know, Europe PMC had a reasonable contribution to adding ROR IDs to Crossref. But I really do hope in time that you can’t even see it.
Amanda French
Yes, in early August 2022, Europe PMC made a very large spike in the DOIs with ROR IDs in Crossref.
Yes, and it’s basically as a direct result of this kind of matching process that we did, so for now it’s substantial. I really hope that publishers will embrace this and start putting ROR IDs in Crossref. And again, then people like me can do some really cool stuff.
Amanda French
What do you hope ROR does in the future? What problems should we fix? What opportunities should we pursue?
Michael Parkin
Phew. For the problem it fixes, as it is now it’s a very good system.
Amanda French
Bug fixes? Feature requests? Suggestions?
Michael Parkin
I mean, the only issues that I had, have kind of been resolved already. They just arrived a little too late for us. The way we get ROR information into our system is to use those data dumps in Zenodo. What we do is we download the JSON file and we parse it out. We’re actually only interested in a very small bit of information: all we want is the ROR ID and what the ROR registry considers the primary name. There’s a lot of stuff in ROR that’s really interesting. In the future I’d love to do more with the data that’s in there. But for now our use case is fairly limited. We would ideally not have to work with the full JSON dump, but now I think there’s a new CSV copy which we’ll probably switch to because we just need to take two columns. With JSON, we use this command line tool called “jq,” and it’s a little bit more involved. But unfortunately the CSV file didn’t exist when we were starting all of this.
So that was not a problem, but that was a minor inconvenience that you’ve now sorted. And then the other thing would be around improvements to the matching API, but I think that has also been done. At the time the documentation was not so comprehensive. Now I think it is. It’s very clear what to do and the output you’re going to get. At the time I was doing this a year and a half ago it was a bit less clear, but that’s been improved, too. So in terms of the user experience, it’s very good.
Longer term… I mean, ORCID is interesting because you have the PID, but you also have the ORCID record, and I can claim various things to it. The ROR registry does not have the claiming aspect. I wondered if that was a desirable thing or not, because in my head, ORCID and ROR solve the same problem for a different type of thing. But the ORCID organisation has all this flexibility around claiming various bits and pieces to your ORCID record. That proves to be really useful when you want to make connections between things, and we use ORCID as a source of figuring out which of EMBL researchers have published, what grants do they hold, that kind of thing. We actually use their ORCID record to create staff profiles, so you get the little headshot and the list of research publications is just pulled out of the ORCID record for that person. That doesn’t exist for the institution level. The institution doesn’t have the ability to add details to that ROR record. I suspect that is just not in the genetics of ROR. But I wondered if that’s something that there’s interest in. There’s a whole world of complexity, though.
Amanda French
It’s certainly not something that’s on our roadmap now. But what’s funny is that we do get a lot of people sort of assuming that that’s the way ROR works, that we are some kind of membership organization or that as an organization you need to register with us in order to update your record.
Michael Parkin
That you need an account, otherwise it won’t appear.
Amanda French
Right, and none of that is true. Anyone can submit a form and request a change to any record. I’ve certainly done that with organizations I used to be affiliated with, and I said, “Oh, you know, this information should include X, Y, and Z.” But we do actually give a bit of preference to people who are from a particular organization. It’s fairly informal: when we turn things into GitHub issues, we tag it, if it’s a person from that organization who wants to make a change to that organization record. And of course that’s very common. It is usually people’s own organizations that they want to update.
With 105,000 records and more, we would have to have a lot more manpower, I think, to manage 105,000 accounts. But it is interesting. I sometimes wonder what we’d do if we had an edit war between requesters over information in a record. As far as I know, we’ve never had that. We have a curation team that evaluates everything on the merits. Is this a good change? Is this accurate? And we get good advice from others, as well, and the curation team makes the ultimate decisions.
But sometimes I wonder what we’d do if there were competing authorities suggesting what the official name of an organization should be, for instance. We are doing a lot of that, you know. You mentioned as an example earlier changing the primary name in the element in a ROR record to the name in another language. And we’ve been doing a lot of that, because in the data we inherited, most of those names were in English, and so we get a lot of “Hey, we are a Spanish university, can we have our primary name in Spanish?” And we’re happy to do that.
Michael Parkin
I’d say in general I don’t have any big feature requests in terms of new things to do. I’m a bit at a loss, except to keep doing curation. There must be a lot of work behind the scenes that probably no one sees. But yes, with over 100,000 records that must be a lot of work. It’s very important, I think, that people trust that you’re a reliable source of information. I think that with a lot of automated systems, there’s a lot of drift towards things not being quite right or introducing errors. Having a team of humans that can tackle these requests is a really valuable thing. But it’s a lot of time, and it may be something to consider as the usage gets higher and higher, especially if big publishers start making use of ROR, whether that’s going to lead to an increased amount of curation required. And how do you cope with the increase? Because you can automate processes, but then I think you lose a bit of accuracy in the process, or even just a little less of a handle on what exactly is going on.
Amanda French
Right.
Michael Parkin
And the other thing would be the documentation, and the way that you’re always inviting the community to provide feedback on things like schema changes, that’s excellent, partly because it lets people know what’s coming up, and lets you object if you have a strong opinion about that: “Oh no, that doesn’t work for us, have you considered that this might mess up this kind of system.” I just think it’s a really nice way of doing things. But it is very hard to do and do well, and I think ROR does it very well.
Amanda French
That’s wonderful to hear. We rely on it, and it really is enormously helpful if people can even just skim something and bring us their expertise.
Michael Parkin
Yeah, there are a lot of experts out there who might just think of something you haven’t thought of before.
Amanda French
We find that with every feedback round. “Oh, we thought we had a good proposal. But oh, here are the things that we didn’t think about.”
Michael Parkin
And people can ignore it if they’re not interested.
Amanda French
It’s interesting what you said about curation, because we are absolutely seeing that. The rate of curation requests has been going up and up and up. We really have only been doing this kind of curation for about a year and a half, actually, because before that ROR was just synced with GRID. So yeah, we are right now looking at ways to maintain the pace of that curation in the face of an increased number of requests. And I am also always trying to make that a little bit more visible, to show all of the requests that we do get and all of the curation work that does go on. Because it is open and transparent, but it’s on GitHub, where not everybody goes. It’s trying to really show people where that is and what’s happening.
Michael Parkin
But yeah, the volume of work increasing does pose an issue. Scaling has some challenges.
Amanda French
Yes, and we are figuring out what to do about that.
Michael Parkin
I take it that ROR is completely diverged from GRID at this point, so you’re entirely responsible for the data, and there are no updates from GRID to feed into ROR? At this point it’s always a request directly to ROR?
Amanda French
Yes, that’s correct.
Michael Parkin
And presumably no plans to remain in sync?
Amanda French
Well, no, none at all. GRID no longer has public, resolvable IDs. The IDs do exist, but they are using them really only internally in Digital Science products like Dimensions. There are no public updates to GRID at all anymore.
Michael Parkin
I see.
Amanda French
Well, that’s about it from me. Anything else you want to say?
Michael Parkin
No, I’ll let you go.
Amanda French
Thank you so much for you being such a big supporter of ROR in general, and for giving us feedback and coming to our events.
Michael Parkin
My pleasure. Thanks for your time.
See also the press release about Europe PMC’s incorporation of ROR into its Grant Finder. Contact community@ror.org with any questions.
Questions? Want to be featured in a ROR case study? Contact community@ror.org.



.jpg){kind=link}