At Crossref and ROR, we develop and run processes that match metadata at scale, creating relationships between millions of entities in the scholarly record. Over the last few years, we’ve spent a lot of time diving into details about metadata matching strategies, evaluation, and integration. It is quite possibly our favourite thing to talk and write about! But sometimes it is good to step back and look at the problem from a wider perspective. In this blog, the first one in a series about metadata matching, we will cover the very basics of matching: what it is, how we do it, and why we devote so much effort to this problem.
What is metadata matching?
Would you be able to find the DOI for the work referenced in this citation?
Everitt, W. N., & Kalf, H. (2007). The Bessel differential equation and the Hankel transform. Journal of Computational and Applied Mathematics, 208(1), 3–19.
We bet you could! You might begin, for example, by pasting the whole citation, or only the title, into a search engine of your choice. This would probably return multiple results, which you would quickly skim. Then you might click on the links for a few of the top results, those that look promising. Some of the websites you visit might contain a DOI. Perhaps you would briefly compare the metadata provided on the website against what you see in the citation. If most of this information matches (see what we did there?), you would conclude that the DOI from that website is, in fact, the DOI for the cited paper.
Well done! You just performed metadata matching, specifically, bibliographic reference matching. Matching in general can be defined as the task or process of finding an identifier for an item based on its structured or unstructured “description” (in this case: finding a DOI of a cited article based on a citation string).
But matching doesn’t have to just be about citations and DOIs. There are many other instances of matching we can think of, for example:
- finding the ROR ID for an organisation based on an affiliation string,
- finding the ORCID ID for a researcher based on the person’s name and affiliation,
- finding the ROR ID for a funder based on the acknowledgements section of a research paper,
- finding the grant DOI based on an award number and a funder name.
Matching doesn’t have to be done manually. It is possible to develop fully automated strategies for metadata matching and employ them at scale. It is also possible to use a hybrid approach, where automated strategies assist users by providing suggestions.
Developing automated matching strategies is not a trivial task, and if we want to do it right, it takes a great deal of time and effort. This brings us to our next question: is it worth it?
Why do we need matching?
In short, metadata matching gives us a more complete picture of the research nexus by discovering missing relationships between various entities within and throughout the scholarly record:
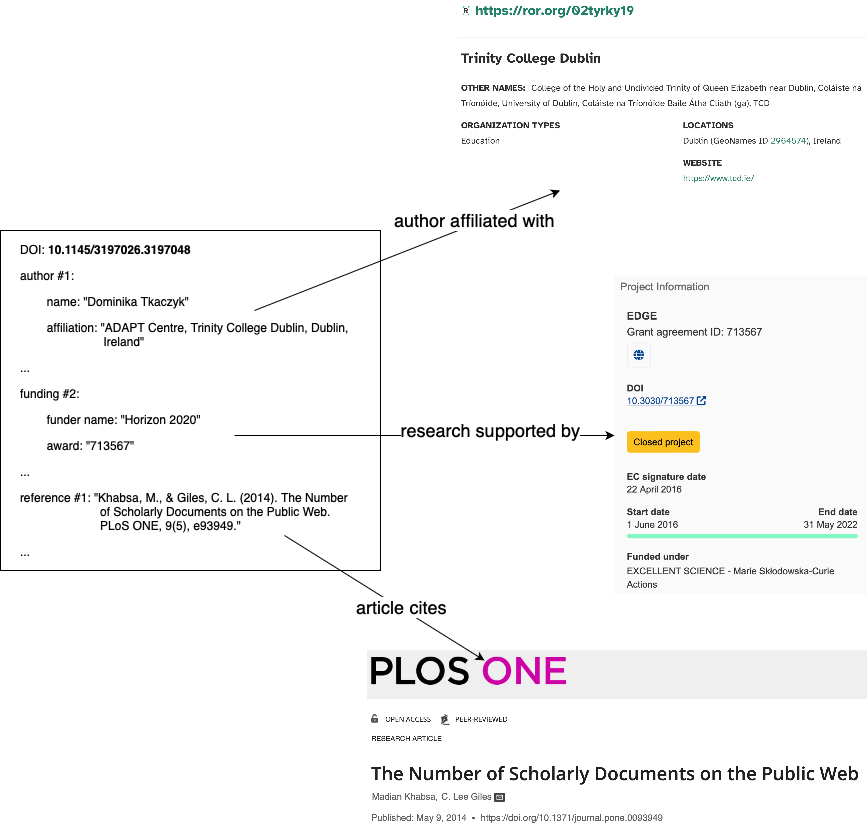
These relationships are very powerful. They provide important context for any entity, whether it is a research output, a funder, a research institution, or an author. Imagine for a moment the scholarly record without any such relationships, where all bibliographic references, affiliations (institution names and addresses), and funding information (funder names and grant titles) are provided as unstructured strings only. In such a world, how would you calculate the number of times a particular research paper was cited? How would you get a list of research outputs supported by a specific funder? It would be incredibly challenging to navigate, summarise, and describe research activities, especially considering the scale. Thankfully, these and many other questions can be answered thanks to metadata matching that discovers relationships between entities in the scholarly record.
There are two primary ways we can use metadata matching in our workflows: as semi-automated tools that help users look up the appropriate identifiers or as fully automated processes that enrich the metadata in various scholarly databases.
The first approach is quite similar to the example we described at the beginning. If you are submitting scholarly metadata, for example of a new article to be published, you can use metadata matching to look up identifiers for the various entities and include these identifiers in the submission. For example, with the help of metadata matching, instead of submitting citation strings, you could provide the DOIs for works cited in the paper and instead of the name and address of your organisation, you could provide its ROR ID. To make this easier for people, metadata submission systems and applications sometimes integrate metadata matching tools into user interfaces.
The second approach allows large, existing sources of scholarly metadata to be enriched with identifiers in a fully automated way. For example, we can match affiliation strings to ROR IDs using a combination of machine learning models and ROR’s default matching service, effectively adding more relationships between people and organisations. We can also compare journal articles and preprints metadata in the Crossref database by calculating similarity scores for titles, authors, and years of publication to match them with each other and provide more relationships between preprints and journal articles. This automated enrichment can be done at any point in time, even after research outputs have been formally published.
There are fundamental differences between these two approaches. The first is done under the supervision of a user, and for the second, the matching strategy makes all the decisions autonomously. As a result, the first approach will typically (although not always) result in better quality matches. By contrast, the second approach is much faster, generally less expensive, and scales to even very large data sources.
In the end, no matter what approach is used, the goal is to achieve a more complete accounting of the relationships between entities in the scholarly record.
This blog is the first one in a series about metadata matching. In the coming weeks, we will cover more detail about the product features related to metadata matching, explain why metadata matching is not a trivial problem, and share how we can develop, assess, compare, and choose matching strategies. Stay tuned!
Feed
Categories
Archives
Tags
- adoption
- annual-meeting
- api
- aps
- caltechdata
- cambridge-university-press
- clarivate
- clear-skies
- coki
- communication
- community
- cris
- cross-post
- crossref
- curation
- curvenote
- data
- datacite
- datasalon
- development
- digicorepro
- digital-science
- discovery
- dryad
- earthscope-consortium
- europe-pmc
- facilities
- fairsharing
- feedback
- figshare
- funders
- governance
- grei
- grid
- guest-post
- hhmi
- hierarchy
- highwire-press
- implementation
- integrations
- interviews
- inveniordm
- janeway
- jobs
- latin-america
- machine-learning
- matching
- metadata
- metadata-game-changers
- mps
- mvr
- nwo
- oareport
- oaworks
- open-access
- open-infrastructure
- openalex
- optica
- orcid
- osf
- persistent-identifiers
- pidapalooza
- pids
- posi
- prototype
- publishers
- publishing
- registry
- repositories
- requests
- research-integrity
- researchequals
- resources
- rockefeller-university-press
- rrid
- schema
- scholastica
- scilifelab
- silverchair
- skgs
- steering-group
- straininfo
- sustainability
- symplectic-elements
- team
- usdot
- web-of-science
- working-group
- zenodo