In this dual case study, we learn why the Howard Hughes Medical Institute (HHMI) relies on OA.Report and why OA.Report relies on ROR to help HHMI track compliance with its open access policy.
Key quotations
“Even back then [in 2019], the best option was to lean on a big, community-owned solution. And it’s been great to see ROR effectively become the standard, the clear way forward for identifying organizations.”
“We think ROR is terrific. We think it’s terrific today, and when we check in and see where ROR is headed, we’re excited. We’re excited to see ROR supersede Funder Registry IDs. We’re excited to see the API and the metadata curation models getting refined over time. And we’re excited to see the ROR team making lots of efforts to get global coverage of research organizations.”
– Joe McArthur, Executive Director, OA.Works
“Another aspect of this that’s definitely relevant here is that what OA.Report is picking up on is not grants or Grant IDs or anything like that, and not even the word ‘HHMI’ just appearing somewhere in the manuscript. It’s actually affiliations. That’s the flag that says to us, ‘This is a paper that you might want to pay attention to.’ "
– Michele Avissar-Whiting, Director of Open Science, Howard Hughes Medical Institute (HHMI)
Amanda French
Let’s start with introductions from you both. Joe, can you tell us your name, title, and organization?
Joe McArthur
I’m Joe McArthur. I’m the Executive Director of OA.Works.
Wonderful. So, Joe, can you tell us about OA.Works and specifically about OA.Report as well?
Joe McArthur
OA.Works is a nonprofit project with the mission to build powerful, simple, open access tools with the vision of a just and kind information age. A lot of what we focus on day to day is building tools that make open access easy and equitable, and OA.Report is one of those tools. OA.Report is designed to help organizations unlock the research that they support, and we have a pretty strong focus on helping organizations implement open access policies. So we’ll do that by helping organizations find the articles that they’ve supported, whether that’s via funding or when their staff have authored it. We help them measure how open that research is, and then take concrete action to increase how much of it is open and increase things like policy compliance.
HHMI is a pretty typical example of our work. We help them track their research output using ROR and figure out how much of it is open access. It will help them figure out the policy compliance, but also other things, like how many articles have data availability statements. I know they’re using a lot of that data to then email authors to ask them to share their work publicly and raise open access policy compliance that way. I think that’s pretty cool. How we do this, I think, is quite neat. We use open data from big scholarly metadata sources like OpenAlex, and also lots of persistent identifiers like ROR, but we also layer in data the institution has that they may be gathering internally, data that only they have.
Amanda French
Do you mean the funder institution?
Joe McArthur
Funders, universities, they all have data that they’ve collected that can help with this task, and it can really help make your way through the open data effectively. And then we layer in on top of that data that we collect and clean in-house just to provide the broadest possible picture that we can for folks of what’s out there and give people the confidence to use that data to take action.
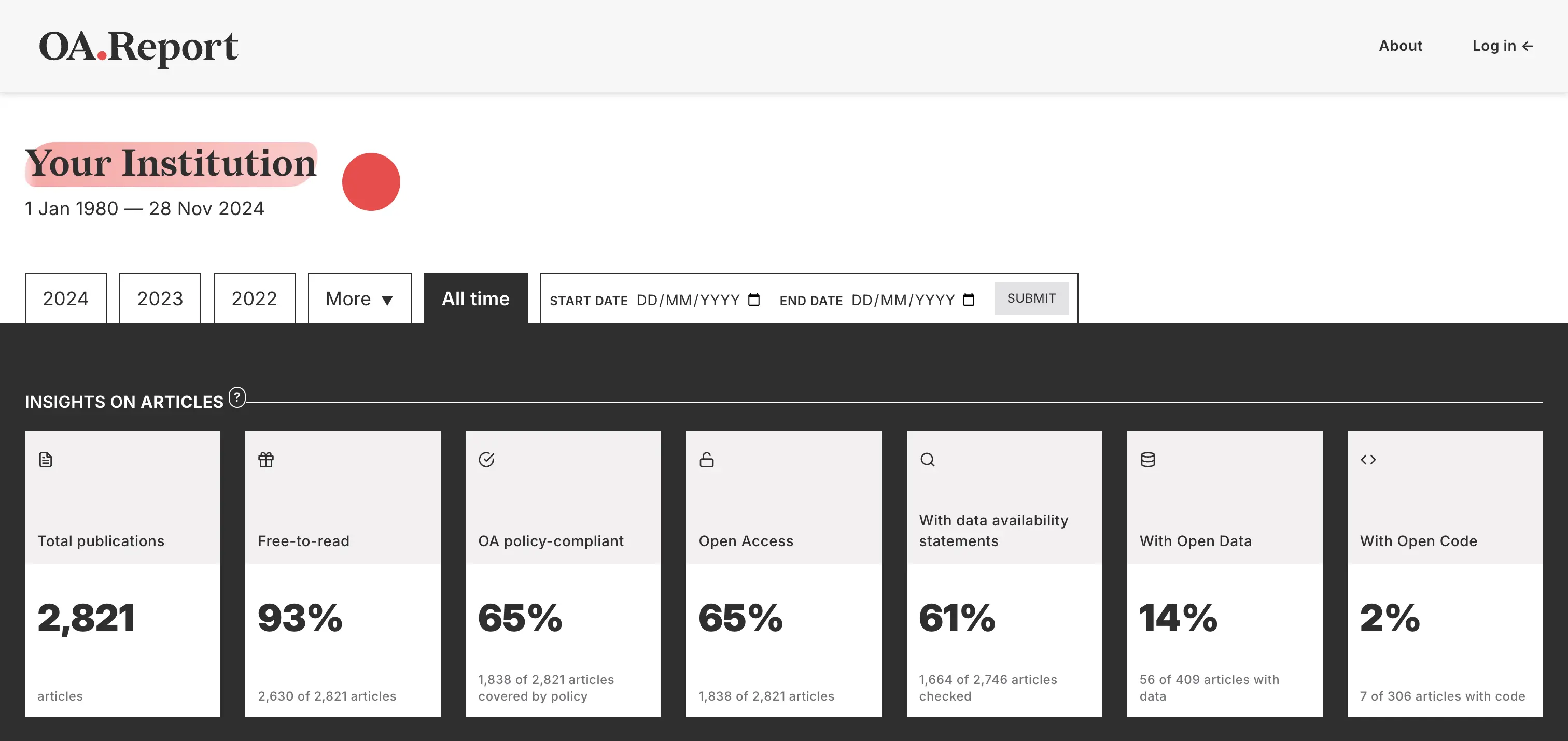
OA.Report sample
Amanda French
Fascinating. I don’t think I knew that it’s not only open data that you’re using.
Joe McArthur
It’s one of the most important parts of the work that we do. We’re massive fans of open data, and there’s so much you can do with it and persistent identifiers, but we do find, perhaps unsurprisingly, that if you enrich that open data with the data people are collecting internally, you can go further.
Amanda French
How do you collect that internal data from universities and funders?
Joe McArthur
During the setup process for OA.Report with institutions, we’ll talk them through the types of data that are often useful to us and work out how that’s going to be shared. The answer almost always is that essentially it will be open data by the by the end of the process. Normally, we work with them to identify what sorts of information they may have internally: that can be anything from previous grant reports stored in grant reporting systems or previous systems for tracking compliance or measuring output. It can be APC invoices, it can be lists of ORCIDs. It can be just names. It’s a whole suite of things, right? What I say is, “Just give that to us in whatever form you have it, and we will take it from there, clean it, do what we need to do, then use that to do output tracking on your behalf and help you figure out what isn’t open, what isn’t policy compliant.”
A classic example of this, and something that we work with a lot, is Grant IDs. We’ll have an initial set of Grant IDs from Crossref, which can, as we all know, unfortunately be incomplete or a bit messy. We will clean those up in-house. We will go out and collect more Grant IDs, and then from an organization’s internal data, we will match those Grant IDs to programs or initiatives inside the organization that may match to multiple Grant IDs or things like that. We’re not actually doing that in HHMI’s case, but that’s a good example of how we thread the needle between all these different data sources.
Amanda French
Fascinating. Michele, I’m going to turn to you now. First of all, just tell us about HHMI.
Michele Avissar-Whiting
HHMI is a research institute. We try to advance science by funding excellent researchers who are doing pioneering scientific research. We do it primarily not through grants: we’re not a traditional funder. We do have some grants, but the vast majority of our investment goes into actually employing researchers in the field at their institutions across the United States. That’s what the Investigator Program is. When you hear “an HHMI investigator,” that’s an investigator who is typically hosted at some other institution but has a dual affiliation with that institution and HHMI. We also have a research facility in Virginia called Janelia Research Campus.
This is relevant, I’m sure, to the conversation that we’re going to have next about how we use OA.Report, but it’s an important foregrounding. It’s an important aspect to how HHMI functions, because we fund people, not projects. We are finding individuals who are doing excellent work already and giving them the resources that they need to get to new breakthroughs in science.
Amanda French
Amazing. Tell us about why HHMI began to use OA.Report.
Michele Avissar-Whiting
On January 1, 2022 we launched our current open access policy, which is a requirement that all major research contributions that are produced by HHMI labs must be shared open access with the CC BY license immediately upon publication. It’s almost like the Nelson memo with the addition of the CC BY license requirement, but we did it earlier in 2022.
I came on about mid-2022 and when I came on, we still didn’t have a mechanism in place to enforce that policy beyond really manual work, just trying to pull in whatever publications we could find through things like PubMed and Lens.org and other databases to track compliance with the policy. So I started looking around. It was actually Ashley Farley at Gates who told me about Joe and OA.Report, saying that we should at least talk. I said, “Our situation is a little bit complex, because it’s not all outputs from HHMI, and not all outputs that are related to HHMI or have a grant from HHMI are subject to the policy. There are very specific criteria around it, so we would need to work with someone who could accommodate those finicky criteria.” And she said, “Just talk to Joe.” So I did, and that ended up being really the key to us being able to keep track of compliance with this policy.
We’ve been with OA.Works ever since. It was a process of probably about a year with a lot of back and forth to refine the specifics around what publications we need to be able to have visibility into and what information we need about them. We define “major contributions” as papers that have an HHMI lab head as the first, last or corresponding author, or a co-author in any of those positions. The first author is often a postdoc or graduate student who wrote the paper, and the last author is usually the principal investigator. The corresponding author is usually also the last author, but not always. So that’s very specific. If they’re a middle author, then that paper isn’t subject to the policy, and we don’t need to care about it for compliance purposes. That’s why OA.Report needs to be able to pick up on the order of authors, which before I spoke to Joe I didn’t know was possible to do. They have to be able to pull that out of the metadata and also to pick up on the metadata that ascribes corresponding authorship, which can be across multiple authors on a paper. So it’s complicated.
It’s also not every type of article type that’s subject to the policy. It’s only original research, so things like reviews and editorials and commentaries are excluded. There’s also a temporal aspect of it, which is becoming less important over time, but which was really annoying in the first year and a half or so that we were working together, which is that we only wanted to find papers that were submitted after the time that the policy went into effect. Submitted, not published, after January 1 2022. That was another piece of metadata that we needed, because if it was submitted on December 22 of 2021, then it’s not subject to the policy. We don’t want to be chasing people down for that.
Open access is a core tenet for us. It’s a massive part of our values. We fund this research so that it can help society, and we don’t think it can do that or be maximally impactful unless it’s free to read, obviously, but also maximally free to use. That’s where the CC BY license with no restrictions comes in. So Joe also needs to be able to pick up on CC BY versus CC BY-NC [non-commercial] versus CC BY-NC-SA [non-commercial, share-alike under the same license] – all of those derivations that are not actually compliant with our policy and that we need people to take action on to fix if they select the wrong license. And this has become the big challenge for us, because there’s a lot of confusion around licenses, and it’s really hard to communicate with authors why this license matters and how it’s being restrictive if you add these other letters to the end of the open license.
Amanda French
I remember the whole learning experience I went through about the difference between CC BY-NC and CC BY. I was opting into non-commercial uses for a long time, and then I realized through a great blog post by Bethany Nowviskie and some other discussion that actually that does cause problems.
Michele Avissar-Whiting
Right - on its face, it seems like maybe the better option, and you think CC BY-NC-ND [non-commercial, no derivative works] might be somewhat more protectionist, but still open. Then you learn that, for example, if you have an NC license, your work can’t be used in a textbook.
Amanda French
The other thing I wanted to mention here is that Crossref is planning a schema update, and one of the things that will be added is CRediT roles for contributors, which might help with that author order problem. It’s not going to put you out of business, Joe, but it’s something that I think a lot of people will appreciate.
Joe McArthur
I mean, I will say that one thing we’re a big fan of is being put out of business! Especially by big open metadata sources. Michele laid out all the challenges for, you know, figuring out whether or not the HHMI policy covers a particular article that may be associated with HHMI. This a problem that we face all the time, and it’s one of the most important pieces for us. What it means to measure policy compliance is to figure out, “Does the policy apply or not?” And it’s surprisingly complicated in a large number of cases, because 90% of the data that Michele mentioned is not available in open metadata in places like Crossref. Or it’s partially there, or it’s there in some sources but not others. So you’ve got to find other ways to get that data, and solving that is a big challenge that we take on at OA.Report.
But we’re really big fans of supporting the long term work that means we don’t have to do this. We don’t want to have to do this. We’d like to be supporting persistent identifiers and, you know, just data structures in the space that get us to not needing to do all of that leg work. We’ve been big proponents of Crossref’s Grant Linking System, and we’ve been working really hard with Crossref to try and speed up adoption of grant DOIs so that grants metadata is better and we don’t need to do so much work. It’s also great to hear that there are schema updates happening that will make it easier to spot the corresponding author, because it’s increasingly important for policies, and it’s really hard to get your hands on unless you are using multiple data sources or else you’re able to just go and read the paper yourself and pull out the corresponding author. That’s what we do now, but we’d prefer not to do it forever.
Michele Avissar-Whiting
And every journal has their own way of demarcating funding and authors. Another aspect of this that’s definitely relevant here is that what OA.Report is picking up on is not grants or Grant IDs or anything like that, and not even the word “HHMI” just appearing somewhere in the manuscript. It’s actually affiliations. That’s the flag that says to us, “This a paper that you might want to pay attention to.” It’s if somebody who’s the first, last, or corresponding author has the HHMI affiliation. And of course, there are name variants. There’s “HHMI” [https://ror.org/006w34k90], there’s “Howard Hughes Medical Institute” [https://ror.org/006w34k90], there’s “Janelia Research Campus” [https://ror.org/013sk6x84], which is part of HHMI. Sometimes people include HHMI with the Janelia Research Campus affiliation, but sometimes they don’t, and that gets into why ROR is necessary.
And sometimes people just don’t put that affiliation, and that’s a problem. That’s probably the next on the list of things for us to tackle with OA.Report, because right now that’s a blind spot for us. If someone just doesn’t put their HHMI affiliation, we don’t see it. I don’t know how often that happens, but it definitely happens with some frequency. So what we would like to do instead is pick up on ORCIDs, and of course those are not used universally, and so that’s another metadata problem. If we could always ensure that we are finding the right author on a paper, then we might not actually need the affiliation anymore.
Amanda French
I look at affiliation metadata in Crossref frequently, to see of course who’s sending ROR IDs to Crossref, but also to see who’s just sending those affiliations. And I’ll tell you, even for new content, I find it surprisingly low. It hovers around 60% of new records that have affiliations. [See ROR IDs in DOI and ORCID records for Crossref API queries that retrieve the number of records with affiliations since 2022 and the total number of records since 2022.]
Michele Avissar-Whiting
Joe, I think you use lots of other data sources, though, including OpenAlex.
Joe McArthur
Yes. The affiliations challenge speaks directly to why ROR is necessary. And yes, in the Crossref metadata, it would be great to see more publishers putting ROR IDs in directly, and I know the ROR team is hard at work nudging people to do that. So that’s awesome. And yes, one source that we work with a lot now is OpenAlex, and they will take that raw affiliation string from Crossref, match that to a ROR ID, and then everyone using OpenAlex gets the lovely benefits of ROR, even if the publisher is not putting them in. That’s one of the incredible things that open metadata and open sources gets us. Now, it would still be better if the publisher was putting the ROR in, but that’s one of the huge advantages of ROR as an open system. And, you know, increasingly, with community standards, people will go out and do that, and that’s really awesome.
There’s places where that’s still not far enough, though. One of the challenges that we see with HHMI data is that multiple affiliations are sometimes not handled fantastically by different systems. I know when we were doing the major author identification, I believe we were using OpenAlex data, Crossref data, PubMed Central data, and Europe PubMed Central data, because each of them was better at a particular slice of getting some of the corresponding, last, and first authors. Some of them were better at having all of the affiliations, but they’d have the authors in the wrong order, whereas some of them were better at having the right order of authors, but not all of the affiliations. It was a whirlwind! But towards the end, we got to a good place.
Michele Avissar-Whiting
I said that maybe if we had reliable ORCIDs for researchers we wouldn’t need the researcher affiliations, but actually it does need to be a sort of triangulation. We also get false positives when people wrongly put HHMI as their affiliation. They have a grant from HHMI, and they or their postdoc wrongly put HHMI as their affiliation. What we really need is some kind of source of truth that could pick up on the ORCID and pick up on the ROR and then see if it’s a part of the list that we have of people who have active appointments at HHMI. That would be the panacea.
Amanda French
I’m on a Committee on Publication Ethics (COPE) affiliations working group that’s addressing that to an extent. Sometimes people are claiming affiliations they don’t have, sometimes in order to get an APC deal, sometimes for prestige, but sometimes also just by mistake. The question came up of whether some kinds of fellowships should count as affiliations. There will be a paper coming out of that that will help at least to outline some definitions about what affiliation means and to make some recommendations about best practices.
Anyway, coming back to you, Joe. You’ve already talked a little bit about this, but why and how do you use ROR?
Joe McArthur
OA.Works has been using ROR as an organization identifier from the very start, since I think 2019. It was in another product just a little bit before OA.Report’s time. Our reason for that was because we wanted an open, community-owned ID that had good coverage globally and was supported by a good team. And you know, that still defines ROR today, except all of those things are more true. Within OA.Reports, ROR IDs are our primary IDs for organizations. We will use that to take a first pass at populating alternative names, relationships, things like that. And then we will use those ROR IDs to go and search other open data sources. If they support ROR, we will just directly go and look at those results, and that will be a lot of how we navigate the open data portion of our work. We’re often using multiple ROR IDs to do that, which as far as we’re concerned is a feature, not a bug. That’s a great thing about ROR. We’re also using the cross-links between between ROR IDs and other IDs, which are a useful starting point for us when we’re starting to get into the weeds with folks.
Amanda French
How did you first come to hear about ROR back in 2019?
Joe McArthur
I wish my memory was good enough to remember! We’ve been at this for over a decade now, and from day one we’ve been putting together open code sharing, open data, and generally being a community-run nonprofit, and so we are always on the lookout for friends. Somewhere around that time I remember that people were excited and talking about it.
And we would have been having conversations internally back then about, like, “How do we identify this organization? Do we come up with some ID internally that we are then shepherding? Do we write just the string, with all the obvious issues that come with that?” Even back then, the best option was to lean on a big, community-owned solution. And it’s been great to see ROR effectively become the standard, the clear way forward for identifying organizations.
Amanda French
I have seen that as well. And even among publishers, who have been slower to adopt ROR, I think they plan to do it: it’s just a question of doing the work. They’ve built all their workflows around other things, and it takes awhile to overhaul those. Just recently, I’ve been focusing a lot on scholarly association publishers, and they’re very open to it. I think over the next one to five years, we’re going to see a lot more ROR IDs coming from publishers in particular.
Joe McArthur
That’s great.
Amanda French
Wrapping up! Joe, do you have any feature requests for ROR, or things you hope we do in the future?
Joe McArthur
I don’t know if I’ve already given it away, but I mean, we are fans. We think ROR is terrific. We think it’s terrific today, and when we check in and see where ROR is headed, we’re excited. We’re excited to see ROR supersede Funder Registry IDs. We’re excited to see the API and the metadata curation models getting refined over time. And we’re excited to see the ROR team making lots of efforts to get global coverage of research organizations. No notes, in many ways.
I would say that an area we are especially supportive of is that as ROR becomes more and more of a standard, it’s important to make sure that it’s more and more representative of organizations, to make sure that we don’t miss any organizations out there that need a ROR. That global coverage is a thing that we think ROR is uniquely positioned to do, and we want to make sure that as we’re trying to support bibliodiversity and make sure that wherever research has been published, it can be found, discovered, used, that ROR is a big part of that. That’s our only “plus one,” really.
That’s really terrific. And that’s exactly the sort of things that we want ROR to be doing and that we’re really grateful for, because we at OA.Works are not going to become experts in Chinese-language organizations, but it’s important that the systems that get built around ROR can take advantage of that. Doing that work at ROR and doing that high level of curation across the dozens of languages that are important in the scholarly literature is just great. I’m really glad to hear that that’s being done.
Amanda French
Yes, that’s ongoing work here at ROR. Michele, what else would you like to say about your work, or about ROR, or about anything at all?
Michele Avissar-Whiting
I don’t know if it’s a question or a comment, but I’m looking at the item types for the ROR record for Howard Hughes Medical Institute, and the organization type is given as “Funder” and “Nonprofit,” which is true. But then, if I go to the record for Janelia Research Campus, which I see has HHMI as its parent, it’s listed as a “Facility.”
Now, the little nuance here is that HHMI, writ large, is a funder, but it’s primarily an institute, so we identify more as an institute than as a funder. What’s not captured in these item types is that the people who are employed by HHMI who are not at Janelia. We’re a little bit of a weird case, but I wonder whether it would make sense to also have HHMI as a “Facility.” As ROR starts to become better integrated into all these publishing systems, I would want Howard Hughes Medical Institute to be in that drop down as an affiliation. It wouldn’t be, necessarily, if it’s only categorized as a funder.
Amanda French
That’s a great note. The first thing I’ll say is that you can request that change if you like, or I can do it for you, and we can take a look at adding that type to the HHMI record. [Note: this change was made in January 2025, a few weeks after the interview took place.] The second thing I’ll say is that, as Joe mentioned, we’ve been doing a lot of work on evolving our schema and API, and one of the things that we’re probably going to look at fairly soon is revising that list of item types, because it isn’t very nuanced. We inherited the list of organization types from GRID, and there’s not very many of them.
The way ROR does this, is we put together a proposal, and then we ask for a lot of community feedback. Once we get to that point, I will be sure to send that to you, because actually edge cases like yours are super useful in making sure that everybody has what they need.
Michele Avissar-Whiting
I am happy to help or contribute to that conversation, however it’s helpful. I just wanted to flag that, because I wouldn’t want HHMI not to show up in a list of affiliations.
Amanda French
I think it would appear in a list of affiliations by virtue of the fact that it’s also listed as a “Nonprofit,” but that’s a good thing to flag. Actually, in version 1 of our schema, all the organizations only had one type, and it was only after we released version 2 that we introduced the “Funder” type and began adding it to records. That’s why most records that have that “Funder” type also have another type, such as “Government.” I’m sure HHMI was originally listed as a “Nonprofit” only, and then we added that “Funder” type to every record with a Funder ID mapping.
Michele Avissar-Whiting
It’s just one of those funny things. We’re always lumped into groups of funders, and, fair enough, we’re part of cOAlition S, and we are part of other funder groups. But even though we’re always considered by other people to be a funder, you’ll never hear somebody within HHMI refer to HHMI as a funder. It’s just interesting.
Amanda French
Anything else from you, Joe, about your work or about ROR?
Joe McArthur
I could say infinite things about both. No, just that we’re really grateful to the ROR team for five years of hard work now. We’re so grateful to the ROR team for providing an infrastructure that so many people can build on. And Michele, we’re grateful to HHMI for getting to work with you for over two years now.