The ROSA P digital repository, operated by the US National Transportation Library – part of the US Department of Transportation – is one of the top ten providers of ROR IDs for publisher identification and ROR IDs for funder identification in DataCite DOI metadata. In this short case study, Peyton Tvrdy tells us why and how her team did such exemplary work in producing metadata for open transportation research funded or produced by USDOT.
This article represents the first in an ongoing series of short case studies on ROR users that we’re calling “Four for ROR” in which we ask ROR users four questions about why and how they’re using ROR.
What made you decide to use ROR?
I was first introduced to ROR IDs Fall 2023 when I started at the National Transportation Library. A coworker of mine, Leighton Christiansen, was introduced to ROR and thought it would be a great idea to create ROR IDs for the Department of Transportation and our sub-organizations. That fall, I used the ROR submission form to create seven ROR IDs for the library. At this time we were unsure of how we would use them and integrate ROR into our repository.
While our repository does not have full ROR integration currently, we use ROR to identify our organizations in our DataCite DOI metadata. I decided to use the ROR API to match our organizations because our cataloging system has many different controlled values of the same organizations. ROR IDs help us to standardize our organization names while still giving proper attribution to organizations in our DataCite DOI metadata. Additionally, because I have a program that uses the DataCite API for DOI updates and maintenance, it was easy to integrate the ROR API for organization matching. Using ROR allows us to better standardize our organizations, fully utilize persistent identifiers, and create better metadata.

Confirming a match to a ROR ID in the DOI parser program
How do you use ROR?
Currently, the National Transportation Library only uses ROR IDs programmatically for our DOI metadata in my DOI parser program. ROR IDs are used for creator organizations, contributing organizations, publishing organizations, and funding organizations. However, ROR IDs are also used in the README files for our datasets in ROSA P. These README files contain important information about datasets, such as funding information, file information, licensing, and the preferred citation.

ROR IDs being used for organizations in a dataset’s README file
What were the steps you took to integrate ROR into your systems and workflows?
Cross-walking our organization names to ROR names and ROR IDs was a lengthy process, but it has resulted in better quality metadata. My program maintains a CSV of our organization names and their mapping to ROR. This allows my program to seamlessly match our organizations to organizations already matched to ROR. For organizations not in this spreadsheet, it queries the ROR API and has the user confirm or manually add a ROR match if there is one. That user response is then saved to the CSV for future use. This lessens the possibility for mistakes as each ROR ID and organization name are only matched once. This process is done for all organization fields in the DataCite schema. Mapping to ROR is especially easy for funder organizations because all of our repository’s research is funded exclusively by the Department of Transportation, so all of our contract and grant numbers are attributed properly to the Department of Transportation.
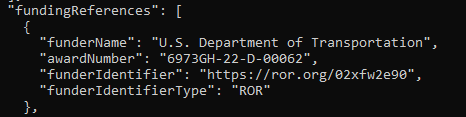
DataCite JSON Metadata of a contract attributed to USDOT with the ROR ID
What else would you like to say about ROR?
ROR as an organization is an amazing resource for organizations looking to standardize and manage their organization names. The staff at ROR and the community calls are excellent resources to learn more about integrating organization persistent identifiers into your repository, documentation, or other processes. While matching controlled values to ROR IDs can be time-consuming, it is worth the effort in the pursuit of linked data.
Feed
Categories
Archives
Tags
- adoption
- annual-meeting
- api
- aps
- caltechdata
- cambridge-university-press
- clarivate
- clear-skies
- coki
- communication
- community
- cris
- cross-post
- crossref
- curation
- curvenote
- data
- datacite
- datasalon
- development
- digicorepro
- digital-science
- discovery
- dryad
- earthscope-consortium
- europe-pmc
- facilities
- fairsharing
- feedback
- figshare
- funders
- governance
- grei
- grid
- guest-post
- hhmi
- hierarchy
- highwire-press
- implementation
- integrations
- interviews
- inveniordm
- janeway
- jobs
- latin-america
- machine-learning
- matching
- metadata
- metadata-game-changers
- mps
- mvr
- nwo
- oareport
- oaworks
- open-access
- open-infrastructure
- openalex
- optica
- orcid
- osf
- persistent-identifiers
- pidapalooza
- pids
- posi
- prototype
- publishing
- registry
- repositories
- requests
- research-integrity
- researchequals
- resources
- rockefeller-university-press
- rrid
- schema
- scholastica
- scilifelab
- scoss
- silverchair
- skgs
- steering-group
- straininfo
- sustainability
- symplectic-elements
- team
- usdot
- web-of-science
- working-group
- zenodo